OCLC News 第38号
商品情報をはじめ、OCLCに関する様々な情報をご案内致します。
『OCLC News』一覧 >>
目次
- スペイン国立研究協議会(Consejo Superior de Investigaciones Científicas)が
OCLCのWSILL(WorldShare® Interlibrary Loan)ユーザーに
- OCLC Researchのリンクトデータ実験プロジェクト「Project Passage」
- ―OCLCのリーダーたちが知見や経験を共有するブログ Nextより―
友人になって人を動かす: 研究支援版
スペイン国立研究協議会(Consejo Superior de Investigaciones Científicas)が
OCLCのWSILL(WorldShare® Interlibrary Loan)ユーザーに

スペイン国立研究協議会 Luis García 撮影[CC BY-SA 3.0 ES]
「世界最大の図書館総合目録である『WorldCat』は最重要大学図書館、科学図書館にとっての本拠地です。スペイン国立研究協議会の図書館文書館のネットワーク目録はスペインで全国的に参照され、海外からのアクセスが必要とされていましたので、世界中からの多くのユーザーにより毎日参照される国際的レファレンスプラットフォームの一部となる必要があったのです。」
アグネス・ポンサチ・オビオルス、スペイン国立研究協議会図書館文書館ネットワーク担当役員
スペイン国立研究協議会について
所在地:スペイン、マドリード
- スペイン最大の公共研究機関
- 研究システム用情報リソース(SIC)の一部であり、研究情報リソースユニット(URICI)を含むネットワークの1つ、スペインの10自治州にある60の研究図書館、14科学文書館、他の科学財団に所属する4つの外部図書館から成る
- スペインの全科学出版物の内およそ20パーセントを刊行
スペイン国立研究協議会(CSIC)図書館文書館ネットワークはスペインおよび世界の科学研究コミュニティーにおいて卓越した役割を果たしています。ネットワーク担当役員のアグネス・ポンサチ・オビオルス氏は次のように説明します。「CSICには公共研究機関として科学的、社会的発展に貢献するミッションがあります。CSICの図書館は様々な方法で寄与、そのミッションを果たしています。豊富な科学的記録遺産を必要とする人々が利用できるようにするのもその1つです。」
CSIC図書館、文書館のスタッフは、WorldCatに200万件を超えるレコードを追加し、世界中の科学研究コミュニティーがそのコレクションを利用しやすくなるようにWorldShare® Interlibrary Loan (ILL)を導入しました。「CSICには世界中の研究者が使用するに値する専門的書誌コレクションがあります。」
「今やインターネット上にないものはほとんど存在しないと言えるでしょう。CSICのコレクションはこの数十年我々のネットワーク上に表示されて利用可能でしたが、このWorldCatとの統合でさらに広く周知されるようになります。」
「CSICには我々の研究者の活動からもたらされた刊行物やデータを自由に閲覧させるという制度上の義務があります。」「ですから我々の機関リポジトリDigital.CSICのWorldCatとの統合はこの協働のもう一つの重要な部分です。」主要なオンライン情報源とOCLCのパートナーシップによってより多くの海外研究者がオープンDigital.CSICのコレクションを発見できるようになります。「特に(WorldCatと)研究者によって幅広く使用されるプラットフォームであるGoogle Scholarとの統合は興味深いです。」「この統合をきっかけに発見、可視化、影響のレベルでの恩恵も期待しています。」
WorldShare ILL はCSICが知識を世界に広めるのを助けてもいます。アグネス・ポンサチ・オビオルス氏によると「CSICはスペイン図書館間貸借サービスにおけるドキュメント提供者として顕著な地位を占めています。」彼女が言及した満足度調査では、研究者が最も価値あるサービスにランク付けし、科学研究の発展における基礎的役割を果たし続けています。「WorldCatへのデータ統合は確実にこのサービスの国際的認知度を上げ、どこからリクエストがあっても我々のコレクションからドキュメントを提供する事に役立つでしょう。」
当記事の詳細はこちらから≫
目次へ戻る▲
OCLC Researchのリンクトデータ実験プロジェクト「Project Passage」

2017年11月から2018年9月にかけてOCLC Researchが行った情報資源のリンクトデータ化実験プロジェクト「Project Passage」についてのレポート「Creating Library Linked Data with Wikibase」が昨年8月に刊行されました。今回はこのレポートからいくつかの事例をご紹介し、将来予定される「書誌レコード」、「典拠レコード」から「リンクトデータ」への移行に関してどのような変化が考えられるか、また課題は何かを見ていきましょう。
Project Passageについて
アメリカ国内16機関の図書館から目録のエキスパートが参加し、オープンソースソフトウェアのウィキベースを使用して実際にリンクトデータを作成し、現在のデータ作成基準以上の精度でデータ化が可能か、ユーザー主導のオントロジー設計やその維持が可能か等の知見を得るためのプロジェクトです。参加者は特にリンクトデータの技術的構造などの知識を必要とされず、課題に対して直にウィキベースを使用して、プロンプトに答えての入力等でProject Passageの環境に構造化されたデータを入力していきました。
データ作成は以下のように行います。ウェブユーザーインターフェイスのProject Passage Retriever で外部の情報であるウィキデータ、VIAF(バーチャル国際典拠ファイル)、FAST(Faceted Application of Subject Terminology 米国議会図書館件名標目表の簡易版をウェブ上で利用しやすいフォーマットにしたもの)及びローカルファイル等を検索、自動的に変換して取り込みます。この時、既にPassage内にある実体データとの重複が疑われるものを検出します。
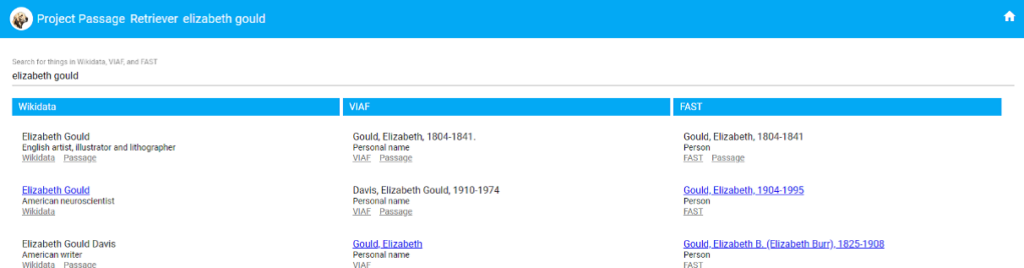
図1:Retrieverでの検索結果
取り込み先はフィンガープリント(後述)画面となっており、内容の追加を行います。
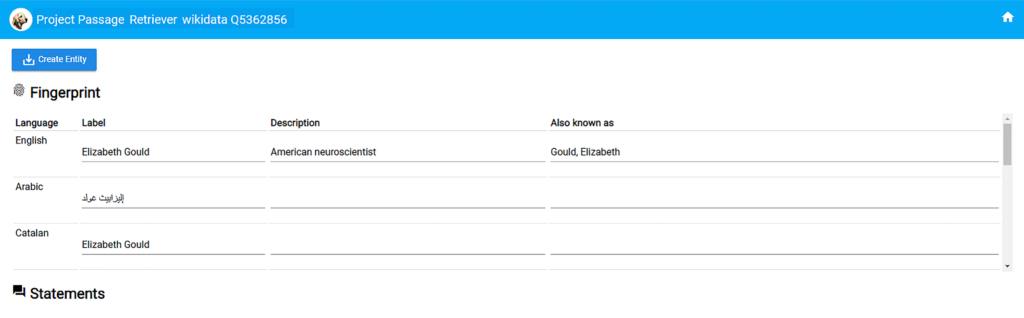
図2:フィンガープリント
フィンガープリントの項目を入力したらCreate EntityボタンでPassage実体データ作成画面に進みます。
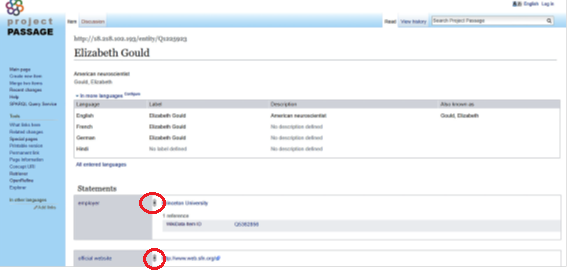
図3:実体データ作成画面
他の実体とのリンクが発生する属性等のステートメント部分を足していきます。もちろん一度作成したら終了という訳ではなく、これ自体も、リンク先も常に変更される可能性のあるデータとなります。それぞれの属性は人の手により「preferred(推奨)」「normal(標準)」「deprecated(非推奨)」の3段階にランク付けされます(赤丸部分はnormalの印が表示されている)。
またプロジェクト中、参加者からの意見を取り入れて作成中のデータにおける各部分の連携をフィードバックするインターフェイスPassage Explorerが追加されました。
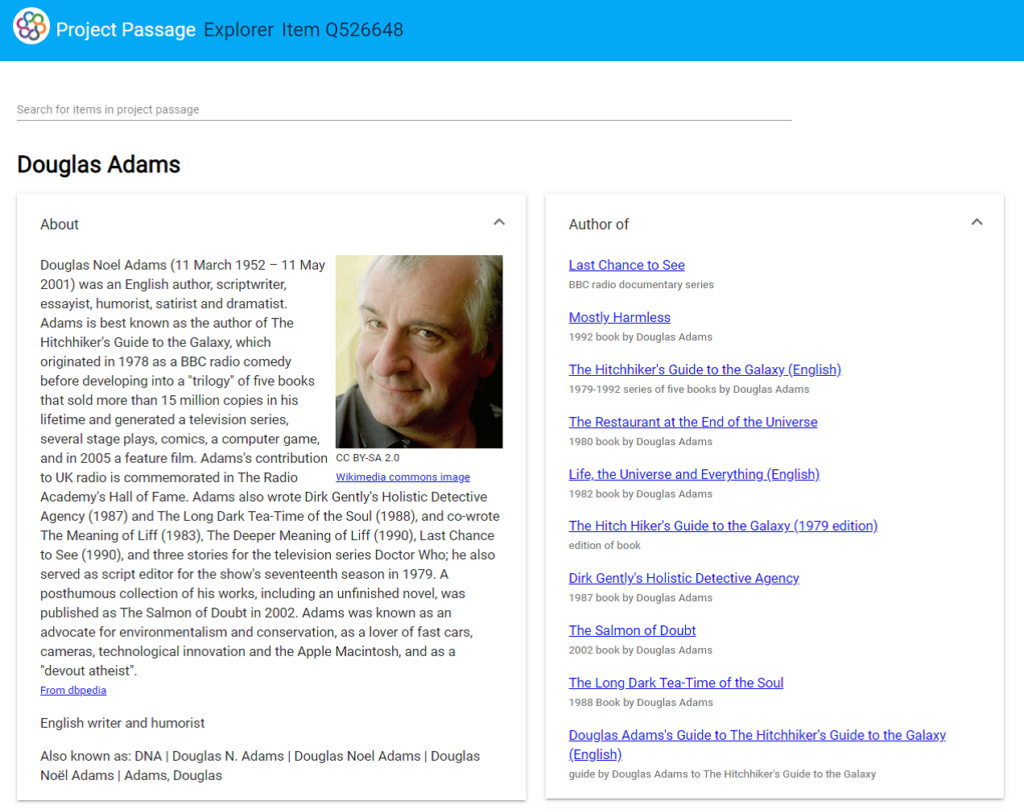
図4:Explorerインターフェイス画面;RDF triple storeから著作一覧、Wikimedia Commonsからポート レイト、DBpediaから経歴を抽出、連携している
事例1:著作「存在と時間」(著作と翻訳との関係をどのように表現するか)
最初の課題としてドイツの哲学者ハイデガーの著作「存在と時間」が与えられました。多数の言語への翻訳が出版されている著作の書誌データについて考察する事ができると考えられます。
ドイツ語の原著「Sein und Zeit」、各国語のそれぞれの翻訳に対し、ラベル(Label)、説明(Description)、別名(Also known as)から成るフィンガープリントを作成しました。
以下は原著の英語フィンガープリントと英訳のフィンガープリント例です。Also known asの部分は他言語での別名が後から追加される可能性があります。
表1:「存在と時間」の原著と英訳に対する英語表示用フィンガープリントラベル

フィンガープリントデータはウィキベースのページ構成で上部に表示されるもので、またブラウザーで選択した言語の表示に切り替える時に必要なものです。上記は英語表示のためのもので、著作の場合、ラベルがタイトルであるために「Being and Time」は「Sein und Zeit」ではなく「Being and Time」の翻訳であるかのような誤った印象を与えていますが、原著に対する正規のURLから接続できるウィキベースの実体データでは機械が理解できる形式でより厳密に言語はドイツ語、タイトルは「Sein und Zeit」、出版社は「Max Niemeyer Verlag」と表記されています。 プロジェクトでは属性の作成時に使用するため事前にSPARQLというRDF(Resource Description Framework)クエリ言語を使用して著作と翻訳に対する以下のクエリを設定していました。
著作に対するクエリ:
- オリジナルのタイトル(オリジナルの文字で)
- オリジナルの言語
- インスタンス(例:図書)
- オリジナルの著者
- 分かっている最古の出版年
翻訳に対するクエリ:
- 翻訳タイトル
- 翻訳言語
- インスタンス(「翻訳」としての)
- 翻訳者
- 翻訳の基となった著作のタイトル
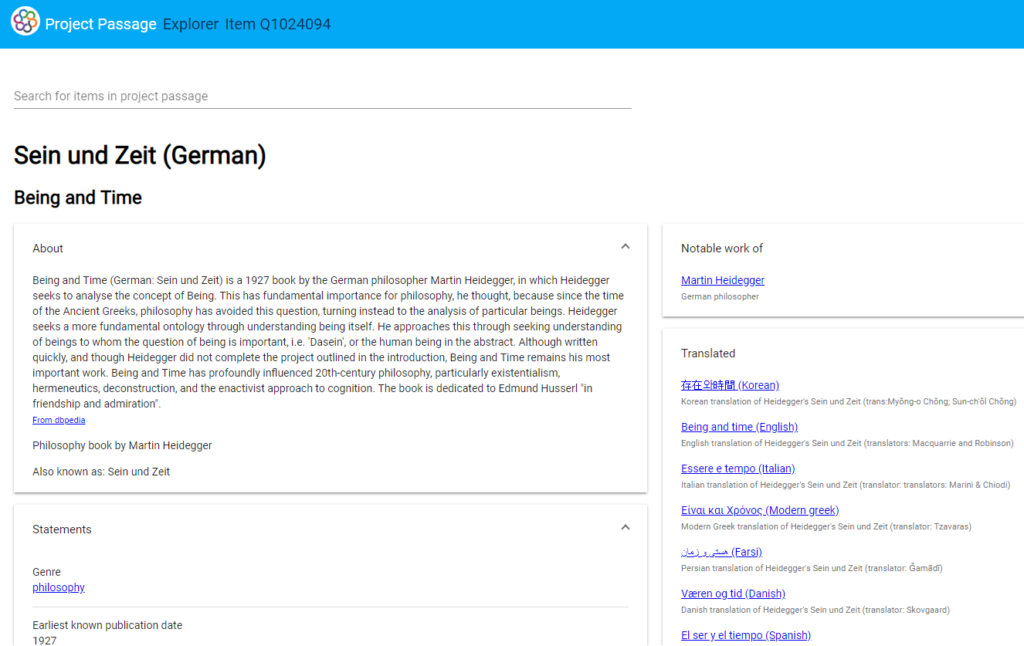
図5:Project Passageでの「存在と時間」データ(部分) 全体図はこちら
以下は原著と翻訳のデータ関係を簡略に示したものです。

図6:英語表示の際の「存在と時間」主要項目と3種類の翻訳の主要項目
プロジェクトの参加者達は原著と各翻訳に相互のリンクを含めるというベストプラクティス推奨案について討議した結果、新しい翻訳が出版される度に原著のデータへ「translated to」という属性を追加、維持していく事は非常に困難という理由でこれを却下、翻訳データに「translated from」を入力するのみとしました。ただし、ウィキベースに組み込まれたUI機能により、原著データで「What links here」をクリックする事で関連した実体として翻訳データを表示する事ができます。
情報発見に関連した演習としてOCLCはPassageのRDFデータセットにSPARQLを使用したクエリを作成しました。このクエリはPassage内で「存在と時間」の翻訳を表す実体を要求するものです。該当するものがあれば、結果として目的の言語と文字でのタイトル、翻訳者、翻訳言語の英語名、最古の出版年を返します。検索結果はウィキベースの視覚化ツール形式で時系列順に表示する事ができます。各実体の一番下の行にあるQで始まる番号はPassege内での各実体のユニークな番号で、オリジナルの「存在と時間」(Q1024094)に紐付いています。
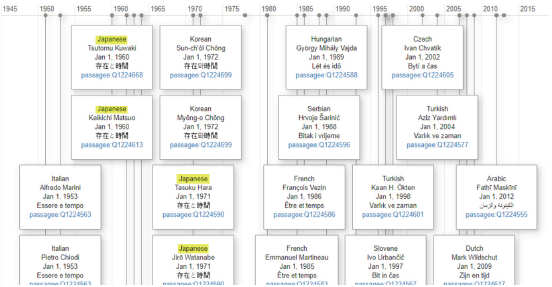 図7:Passage内にある「存在と時間」の翻訳の時系列表示(部分) 全体図とクエリ内容はこちら
図7:Passage内にある「存在と時間」の翻訳の時系列表示(部分) 全体図とクエリ内容はこちら
このような視覚化で学術調査にとって色々と重要な事が分かります。まず、「存在と時間」が言語や文化の境界を越えて移動していった経路を知る事ができます。また、同言語に翻訳された複数のバージョンを同時に確認できます。例えば黄色いマーカーがついているのはそれぞれ別の翻訳者による日本語訳です。ドイツ語から日本語のようにまったく異なる言語に翻訳された場合、翻訳によって著しい違いが生じる可能性があるので、それぞれの翻訳者を区別する事が必要となります。
事例2:個人名「孫文」(各国語で標記の異なる人名の典拠をどう表現するか)
また、あるチームには中華民国の国父、政治家、革命家として知られる「孫文」のデータ作成が課題として出されました。ウィキベースを使用してこれを多言語対応する事は現行の典拠レコードが一種類の文字列を唯一の典拠としている事への挑戦でもあります。担当チームは孫文のID Q459121に対しては、表示や検索のインターフェイスの言語設定に応じて英語での表記「Sun Yat-sen」も中国語の標記「孫中山」も推奨形のラベルとして使用できる事に気づきました。以下はブラウザーの言語設定が英語の場合と中国語の場合の「孫文」のウィキベースエディタ表示です。
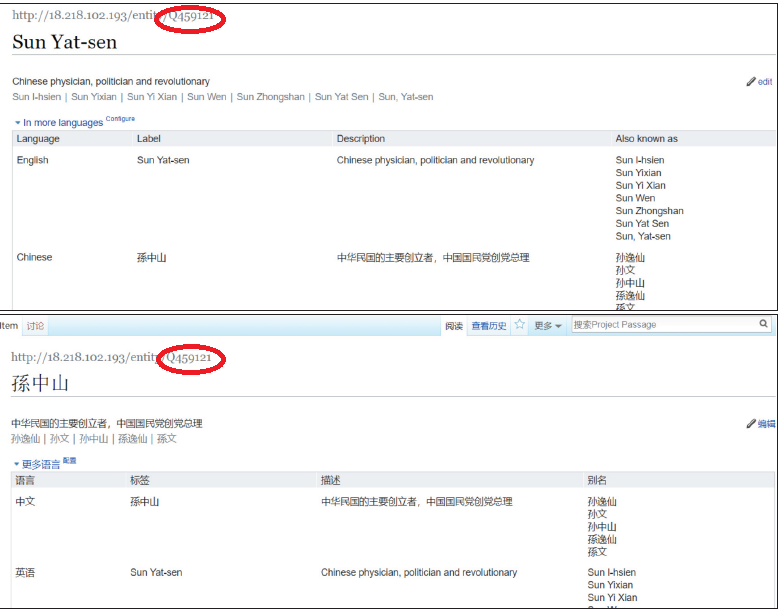
図8:上は英語表示の場合、下は中国語表示の場合
担当チームはカタロガーがあらゆる言語の個人や実世界オブジェクトに対して唯一の典拠形を決定するのに時間を費やす事が最良の方法ではないと確信しました。恐らくもっと重要な仕事は利用者にとって最も使い勝手の良い形を選択できるよう、できる限り多くの言語で記載されたフィンガープリントデータを作成する事でしょう。また、この例では中国語のカタロガーは中国語に対するローマ字ヨミに時間をかける必要がなく、ヒンディー語、朝鮮語、ロシア語、その他の言語の話者のように孫文のような世界的に重要な人物の名前について独自の表記を作成できるという事を示しています。
सन यात – सेन(孫文のヒンディー語表記)
쑨원(孫文の朝鮮語表記)
Сун Ятсен (孫文のロシア語表記)

図9:現在の目録作業で使用されている孫文の典拠レコード(部分)(OCLC Connexion client画面)
*非ラテン文字の国の人物、地名でも典拠形はアルファベット形
以下は既存のウィキデータから抽出した各言語のフィンガープリントですが、これらが情報の溝を埋めてくれる可能性もあります。スペイン語とドイツ語のフィンガープリントは既にそれぞれの言語での説明がついていますが「Also known as(別名)」が含まれていません。ポーランド語のものは別の形式のラベルとなっていますが、説明はデフォルト表示である英語表記のままです。さらにピジン英語のものは母語話者がまだ手を加えていないために英語版から読み込まれたラベルと説明を表示しています。
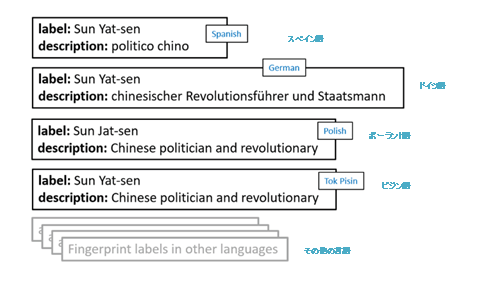 図10:中国語、英語以外の言語のフィンガープリントデータ
図10:中国語、英語以外の言語のフィンガープリントデータ
フィンガープリントデータの基となったウィキデータはこちら
これらのフィンガープリントデータを改善する事により、中国語、英語、スペイン語、ドイツ語以外を母語とする利用者の探索、検索結果が向上します。ウィキベースの多言語機能を代用とすればメタデータ(典拠)作成のワークフローにある曖昧性除去の作業は不要になるだろうと結論付けています。
レポートではこの他にも
- 現存しない中国の地名(ある時代の一定期間にのみ関連する地名を典拠レコードで表現する)
- 古地図(地図の出版時タイトルは重要か、数値データの扱い、地図本体以外部分の扱い)
- コンサートポスター(アーティスト、イベントに関連する2次元非投影グラフィック資料書誌レコードについて)
- 歴史上の人物の写真入り絵葉書(多数の別名を持つ王族が歴史的出来事に関連した扮装で撮影された場合)
- 写真(歴史上の人物が歴史的な場面で写っているものと無名の集団が写っているもの)
古地図から写真について:イメージ資料に投影されている実体を言語化、”depicts”としてリンクトデータ化するが、そこからこぼれ落ちるコンテキストはフィンガープリント内の構造化されていないdescriptionに行くしかないのか?
- 大聖堂の献堂式に演奏された楽曲の楽譜(宗教的イベント、場所に関連する楽譜資料書誌レコードについて)
をデータ作成事例として取り上げ、プロジェクトから得た7つの教訓を以下のようにまとめています。
- ウィキベースの実体構成要素は簡単な手順により、現在の図書館データ標準を超える精度で構造化データを作成する事ができる。 しかし、このデータを使用して、資源の発見と解釈に必須のコンテキストを構築できるのか?
- ウィキベースプラットフォームで利用者主導のオントロジー設計ができるのは望ましいが、長期にわたって維持管理する方法は?
- ウィキベースプラットフォームにOCLCで拡張機能を付与し、スタンドアロンユーティリティで補完する事により図書館員が作業中のフィードバックを得られるようになった。
- ローカルデータの管理には堅牢なツールが必要。
- 図書館のデータをナレッジグラフに登録するために外部で作成されたデータの取り込みや拡張を手助けするツールを推奨。
- 実験プロジェクトではデータの取り込みと出力の両面においてリソース間の相互運用の必要性が強調された。
- ウィキベースのデータ編集インターフェイス内で作成された記述では、伝統的な典拠、書誌レコードの差異が消滅する。
レポートの全文はこちらから≫
プロジェクト参加者のNextブログ≫
目次へ戻る▲
―OCLCのリーダーたちが知見や経験を共有するブログ Nextより―
友人になって人を動かす: 研究支援版
ブライアン・ラヴォア OCLC Research

研究支援サービスは大学の研究事業にとって不可欠なものです――研究者の生産性を高め、研究活動分析を容易にし、研究成果を世に出して学術コミュニティー内外でアクセス可能とする。研究支援サービスはキャンパス全体はもちろんの事、研究のライフサイクル全体に及びます。
研究支援はどのように行われるのでしょうか。 大学内で行われそうないくつかの例を挙げてみましょう。
- 大学の研究者がデータセットを学内ITサービスと図書館が共同管理するデータリポジトリに保管する。
- 教養学部の管理者が研究室運営の研究情報管理システムから得たデータを分析する事によって機関の研究で強みをもつ領域を確認する。
- 研究開発室と図書館が協賛する取り組みによって教職員が個人プロフィールを作成し、専門知識を強調し、研究協力関係を明示する事ができる。
OCLCの新しい研究プロジェクト、「研究支援における機関関係者」は研究支援に関する実りあるキャンパスパートナーシップを構築するための重要な教訓を明らかにするという目的を持ち、研究支援サービスにおける学内利害関係者の範囲を調査します。
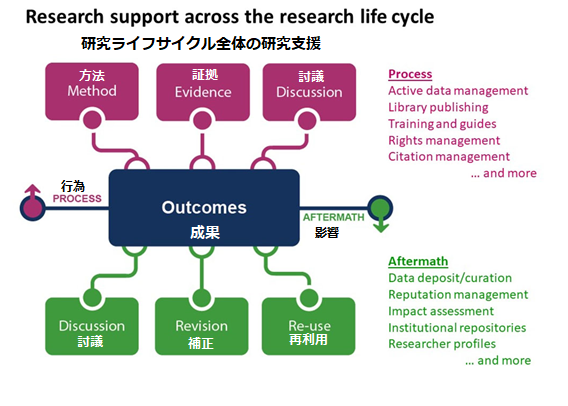 出典:The Evolving Scholarly Record (OCLC Research, 2014)
出典:The Evolving Scholarly Record (OCLC Research, 2014)
大学図書館は研究支援サービスの重要な学内プロバイダーですが、図書館が唯一のものではありません。上述の例が示すように多くの大学部署が研究支援に関わる事ができるのです。そしてこれらのサービスが複数の大学部署間のパートナーシップを通じて提供される事が度々あります。――例えば、図書館が管理し、学内のコンピューティング資源を経由して配置されている機関リポジトリです。さらにこのサービスの利用者は研究者だけでなく情報関係部署や教務のような大学事務所にまでキャンパス全体に広がっています。
つまり研究支援サービスは多くの方法で――複数の学内プロバイダー間のサービス配信を通じてであったり、サービス提供を複数部署で協力していたり、サービス利用者間の広範なキャンパスネットワークだったりする事でキャンパス全体に広がっているのです。
パートナーを知る: 6つの質問
研究支援サービスにおける効果的な関与には図書館が多様な大学部署と連携する事が必要かもしれません。それらのいくつかは図書館と深いつながりを持って長期間続くパートナーとなる場合もあり、また一方で表面的に親しいだけの関係となる場合もあります。優れた協力体制とはパートナーを知る事です。一緒に働く学内パートナーについて考えてみましょう。以下の質問の内いくつに答えられますか?
- 彼らは何をしていますか?
- その事はなぜ重要なのですか?
- 彼らはどのようにそれを行っていますか?
- 彼らの責務にとってどのような学内での関係が不可欠ですか?
- 彼らが提供する固有のスキルや能力は何ですか?
- 彼らの「弱点」は何ですか?
頑丈で生産的な学内パートナーシップは、必要とするものと能力という両観点からそれぞれが提示したものをしっかり相互に理解した上で築く必要があります。
OCLCリサーチのプロジェクト「研究支援サービスにおける機関関係者」は、研究支援サービスの分野で学内パートナーと協働する際に図書館スタッフが直面する可能性のある知識格差を埋める事を意図しています。プロジェクトの主要部分は私たちがアメリカの大学の幅広い部署、学内コンピューティング、大学院研究、学長事務所、研究室、教務等で働く個人に対して行った一連のインタビューです。私達の目的は彼らの話を聞き、彼らの経験から学び、彼らの部署が行っている事、研究支援における関心事、研究支援において利害関係者との学内での関係をどのようにして成功させようとしているのかを知る事です。
インタビュー完了後、私達は結果を統合し、情報提供者が関係した多種多様な経験から一般的な「教訓」を引き出します。プロジェクトで発見したものによって図書館が研究支援サービスに関連した学内パートナーシップを成功に導くための準備が整う事を期待しています。
友人となって人を動かす
自己啓発本の著者で演説家のデール・カーネギーは彼の有名な著作、「人を動かす (How to Win Friends and Influence People)」の中でこのような助言をしています。「他人に関心を持つようになれば、他人に自分への関心を向けさせる事によって2年間で得るよりも多くの友人を2か月で作る事ができる。」
私達はまだ研究結果を組み立てているところですが、1つ重要な点がカーネギーによって予言されています。それはこれまで行ってきたインタビューの間中ずっと心に響いており、研究の前提を強固にしているのです。
生産的で持続可能な関係を築くためには参加者がお互いについて学ぶ必要がある。図書館は予想される学内パートナーについてできる限り多く学ぶことによって研究支援サービスの提供に対してより効果的に関与する事ができる。私たちの研究がそのような方向への第一歩となる事を願っています。
当記事の詳細はこちらから≫
目次へ戻る▲
(紀伊國屋書店OCLCセンター)