新しい方法論としての「デジタル人文学」
近年、英米を中心に一次資料のデジタル化・データベース化がすすみ、歴史・文学・社会・法律・経済など人文・社会科学系の研究者は、従来からは考えられないほど多彩かつ膨大な一次資料に比較的簡便にアクセスできるようになりました。一方で、新たな研究手法として、膨大な一次資料データにテキストマイニングや自然言語処理など情報科学のノウハウを応用することにより、資料群をコーパスとして統計的・俯瞰的に分析する、いわゆる「デジタル人文学」や「人文情報学」も盛んとなってきています。
研究者の参入をはばむ技術的・実務的障壁
しかしながら、そうしたデジタル人文学の分析手法は多くの場合、既存のデータベースの枠組みの外で行われるため、多くの研究者にとっては、プログラミング技術やノウハウの習得、分析対象となる一次資料元データの探索・収集、版権所有者への許諾申請、データ形式の整理と統一、ローカル・サーバーへのホスティングと適切な管理、分析結果のビジュアル化、他の研究者との共有など、数多くのハードルが存在し、ごく一部の研究者やプロジェクトチームをのぞいて、多くの人文系研究者、とりわけ歴史系の研究者にとっては敷居が高く感じられる分野であることも事実です。
Gale コンテンツのテキストマイニング・プラットフォーム
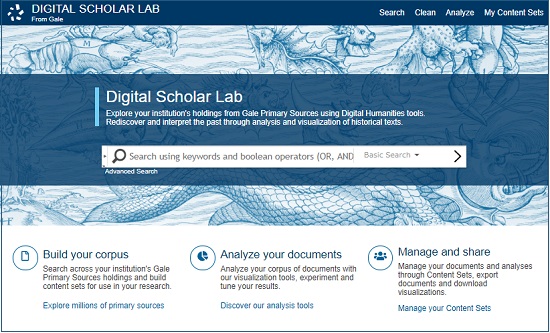
そこでGaleでは、イギリスを代表する新聞の「Times Digital Archive」、社会経済史文献の「The Making of the Modern World (MOMW)」など、これまで数多くのデジタル一次資料群を構築・リリースしてきた経験を生かし、デジタル人文学を実践する研究者の助言やフィードバックのもと、弊社データベースのコンテンツについて、オンライン上で直感的にテキストマイニングを行うことができる新プラットフォーム「Gale Digital Scholar Lab」をリリースしました。
より広いユーザー層にデジタル人文学の底辺を拡大
「Gale Digital Scholar Lab」により、歴史分野で定評のあるGale のアーカイブ・コンテンツをコーパスとするテキストマイニングがオンライン上で、手軽にできるようになるばかりでなく、作成した分析結果の共有、履歴の保存や修正などもクラウド上で行うことができるようになり、デジタル人文学的手法に興味がありながらも、技術面の抵抗から躊躇してきた研究者や、院生・学部生を含め、テキストマイニングの裾野がいっそう広がることが期待されます。また、データ形式がすでに統一されており、定評あるオープンソース・ツールを多く採用し、OCR テキストのダウンロードも可能にしているため、すでにデジタル人文学を実践している研究者も、Gale コンテンツを用いた分析への糸口として利用できます。
Gale Digital Scholar Labの特色
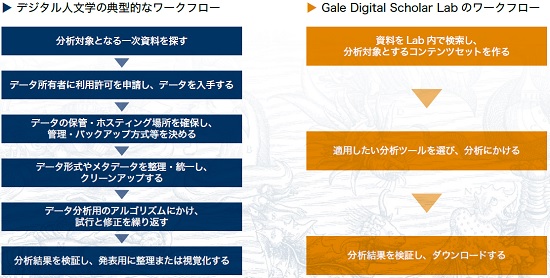
- Gale社の一次資料1億 6600 万ページ分のテキストデータを搭載することができます。
- プログラミング等の知識は必要ありません。
- OCRテキストをダウンロードすることができます(1セッションあたり1,000 件まで)。
- 各文献について、OCRテキストと元画像を対照表示させることができます。

本文画像とOCRテキストの対照表示
- トピック・モデリング、クラスタリング、Nグラム頻度、固有表現抽出など、6種類の分析ツールをオンラインで適用することができます。
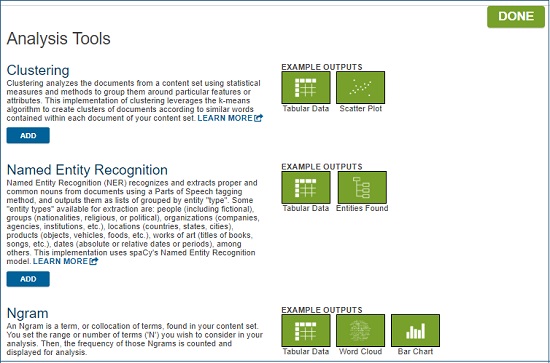
分析ツール選択画面
- 分析結果のエクスポートも可能です。
- 検索履歴・分析ツール使用履歴等を保存し、後から再現することができます。
- Google、Microsoftの各アカウントからのログインが可能です。
- クラウドベースで利用するため、サーバーを管理する必要がありません。
Gale Digital Scholar Labのメリット
- Galeの定評あるコンテンツ群のテキストを簡単に分析にかけることができます。
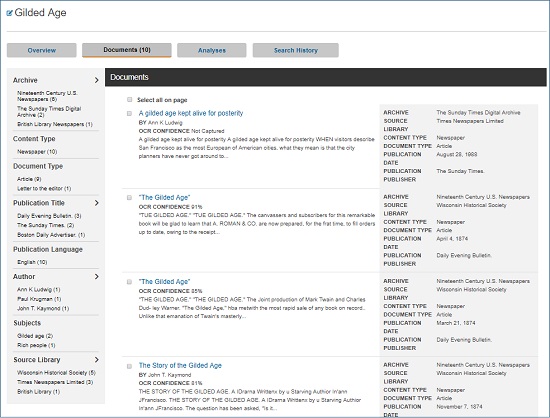
コンテンツセット編集画面
- プログラミングなどの技能を必要としないため、研究者や学生が幅広く利用することができます。
- 個々の文献の閲読からは見極めが難しい、文書群全体に頻出する用語やテーマなどを抽出・分析することができます。
- 分析結果を簡単に視覚化し、共有・発表できます。
- 実行履歴から分析結果を繰り返し再現することができます。
- 統一されたデータ形式でメタデータも揃っているため、データ最適化に時間を費やす必要がありません。
- クラウドベースのため、データの保管やメンテナンスにかかる手間をはぶくことができます。
- デジタル人文学の入門講座等でも利用することができます。
- OCRテキストのダウンロードにより、外部ツールを用いた分析ニーズにも対応することができます。
- 日本語文献や国内所蔵文献にかたよりがちなデジタル人文学プロジェクトを西欧文献に広げることができます。
- 図書館によるサポートも簡単です。
- 図書館で所蔵しているGaleコンテンツを生かした新たな研究成果の発信が期待できます。
Gale Digital Scholar Labで利用可能な分析ツール
デジタル人文学の研究者によるフィードバックをもとに、テキストマイニングで広く使われている、汎用性の高いツールを採用しました。Gale Digital Scholar Lab 内では、マウスのクリックや簡単な設定で実行できるように工夫されており、プログラミング等の知識は必要ありません。出力形式も視覚的なグラフ形式等だけでなく、表形式も備えています。ツールは今後も、ユーザーからのフィードバックをもとに、新たに追加・改良されていく予定です。

Nグラム頻度(Ngram)
- 元となるライブラリ:Lucene
- 主な用途:頻出単語・フレーズの抽出
- 出力形式:ワードクラウド、棒グラフ、表形式
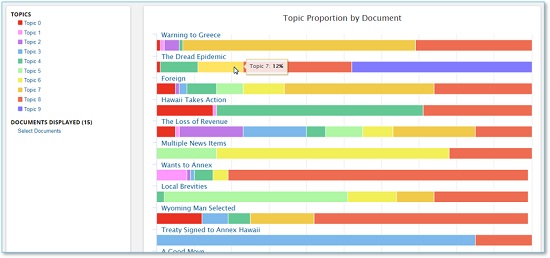
トピック・モデリング(Topic Modelling)
- 元となるライブラリ:Mallet
- 主な用途:複数の文書に共通するトピック群の抽出
- 出力形式:トピック表示、比較表示、比率表示、表形式
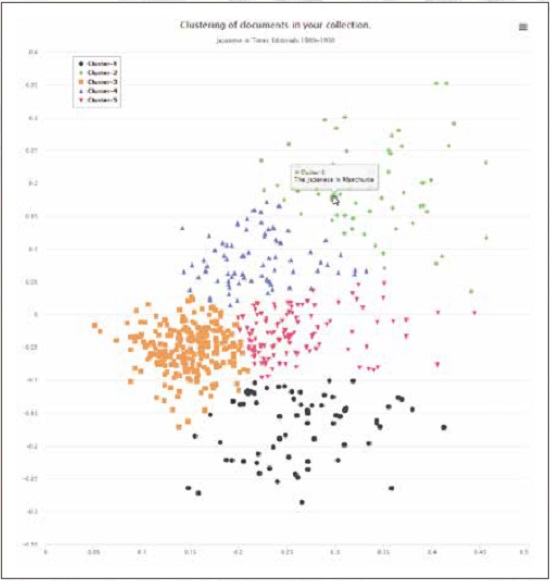
クラスタリング(Clustering)
- 元となるライブラリ:SciKit learn
- 主な用途:文書を類縁性で分類
- 出力形式:座標形式、表形式
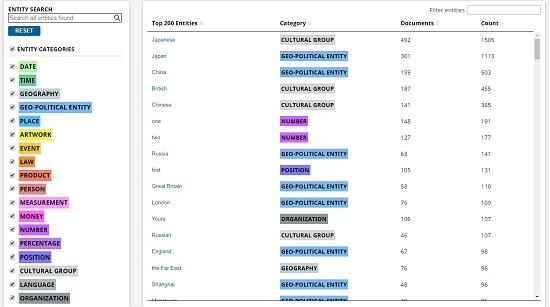
固有表現抽出(Named Entity Recognition)
- 元となるライブラリ:spaCy
- 主な用途:固有名詞・数字・日付等の抽出
- 出力形式:種別表示、文書内表示、表形式
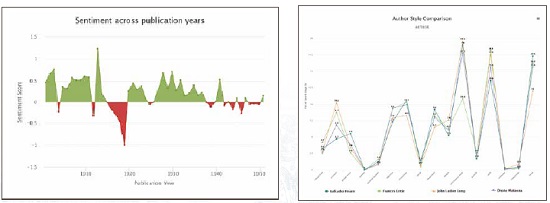
左:感情分析(Sentiment Analysis)
- 元となるライブラリ:OpenNLP
- 主な用途:文書内容が肯定的か否定的かを分析
- 出力形式:年代別グラフ形式、表形式
右:品詞タグ付け(Parts-of-Speech Tagger)
- 元となるライブラリ:spaCy
- 主な用途:著者ごとに品詞の使用頻度を比較
- 出力形式:著者別グラフ形式、表形式
Gale Digital Scholar Labで利用可能なコンテンツ
Gale Digital Scholar Lab では、Gale Primary Sources コンテンツの大半のデータを搭載することが可能です。
契約時にご利用いただけるのは、ご導入いただいているコンテンツのみとなります。今後、新たにリリースされるコンテンツ群も順次、Gale Digital Scholar Labで利用可能となる予定です。
一部のコンテンツ群は、技術上の障壁や権利者の意向などにより、現時点でGale Digital Scholar Labに搭載できません。
※Gale Digital Scholar Labで利用可能なコンテンツに関しては、紀伊國屋書店までお問い合わせください。
Gale Digital Scholar Lab の今後
デジタル人文学の分野において次々と斬新な手法やアプローチが試されているように、Gale Digital Scholar Lab も ユーザーからのフィードバックやニーズにあわせて、絶えず改良・改善されていく予定です。
進化しつづけるGale Digital Scholar Lab に今後もご注目ください。