OCLC News 第50号
商品情報をはじめ、OCLCに関する様々な情報をご案内致します。
『OCLC News』一覧 >>
目次
- OCLC News 50号特別企画 OCLCあの時この時
- ―OCLC ResearchのブログHanging Togetherより― 次世代メタデータに関する初の英語円卓会議: 相互運用可能な図書館データのクリティカル・マス*を目指して
- フェイエットビル公共図書館(FPL)がOCLC Wiseを導入 ―FPLが目指す「究極の図書館体験」―
- OCLC Interlibrary Loan Cost CalculatorでILL料金を算出
OCLC News 50号特別企画
OCLCあの時この時
お陰様でOCLC Newsも今号で50号という節目を迎えました。そこで特別企画としてOCLCが1967-2005年に発行していたOCLC Newsletter (1973年までは Newsletter)から、日本に関係した記事をご紹介します。
OCLC Newsletter no. 170 (Oct./Nov. 1987)より”OCLC CJK 350 benefits 54 libraries”

「OCLC CJK350システムが54の図書館に恩恵を」アンドリュー H. ワン
34年前の1987年、この年の1月にサービスを開始したCJK350システムの紹介記事です。CJKは中国語 (Chinese)、日本語 (Japanese)、韓国/朝鮮語 (Korean)の頭文字で、この3つの言語資料の目録データをOCLCのWorldCatデータベースに登録したり、目録カードを印刷するためのソフトウェアがCJK350システムで、これを使用するには専用端末CJK350が必要でした。
専用端末とは、現在考えると不思議な感じさえしますが、当時はインターネットもWindowsもユニコードもなかった時代です。漢字、ひらがな、カタカナ、ハングルというバナキュラー文字 (その言語で使用している非ラテン文字) を入力して欧米のデータベースに登録するためには専用の端末機が必要だったのです。CJK350ができる以前にもCJK資料の書誌レコードはWorldCat (当時はOCLC Online Union Catalogと言っていました) に存在しましたが、バナキュラーが入力できませんので、ローマ字での翻字フィールドと英語の記述のみで作成されていました。
CJK350の登場で、新規にバナキュラーの入った書誌レコードの作成が可能になっただけでなく、ローマンアルファベットのみで入力されたWorldCat内の既存書誌レコードにバナキュラーを追加してグレードアップする事ができるようになったのです。WorldCat内部でバナキュラー文字はEACC (East Asian Character Codes) という3バイトコードで保存されました。このコードは、繁体字と簡体字、旧字と新字など同じ文字の異体字を正規化できるようコードの下4桁に同じ数字を持たせる形式になっています。(現在WorldCatはユニコードでの入力が可能です。)
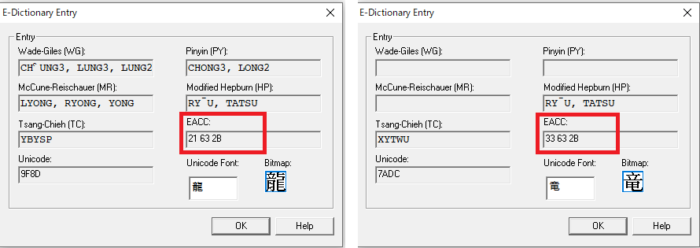
「龍」と「竜」のEACCコード (Connexion clientのCJK E-Dictionaryより)
当時のバナキュラー文字入力は一文字ずつの変換 (!)で、変換方式は中国語がTsang-chieh コード (部首を表すコードを組み合わせる)、Pinyinヨミ、Wade-Giles ヨミの3種類、日本語は修正ヘボン式ヨミ、韓国/朝鮮語はMcCune-Reischauer 式ヨミで変換するというものです。以下はCJK350で入力された最初のバナキュラー入り書誌レコードです。インディアナ大学が1986年のフィールドテストの際に作成したものです。最初のCJKレコードは日本語の図書だったのですね。当時はこういった書誌レコードを通常のOCLC端末で表示させるとローマンアルファベットのフィールドのみが表示されていました。この時代、日本でのOCLCは洋書を処理する際の補助的ツールと受け止められていましたので、日本でCJK350を使用しようという図書館はありませんでした。

最初のCJKレコード (OCLC Newsletter no. 165 (Nov. 1986)より)
OCLC CJK350は、その後1990年代にCJK Plusにバージョンアップし、技術の進歩とともに役目を終える時が来ます。2002年、OCLC Connexionの登場で通常の目録システムCAT ME Plusと統合、ウィンドウズベースの目録システムとなり、MS IMEで通常の日本語入力と同じようにバナキュラー入力ができるようになりました。以下が現在 (2021年4月2日) の同じ書誌レコードです (Connexion client版での表示)。
インターフェイス上、ヨミのローマ字ではなく、バナキュラーが先に表示されるように変わりました (内部のMARCフォーマットは変わりません)。また、13桁のISBNが追加されたり、RDAのフィールド336-338が機械生成されたり、と時の流れを感じさせます。
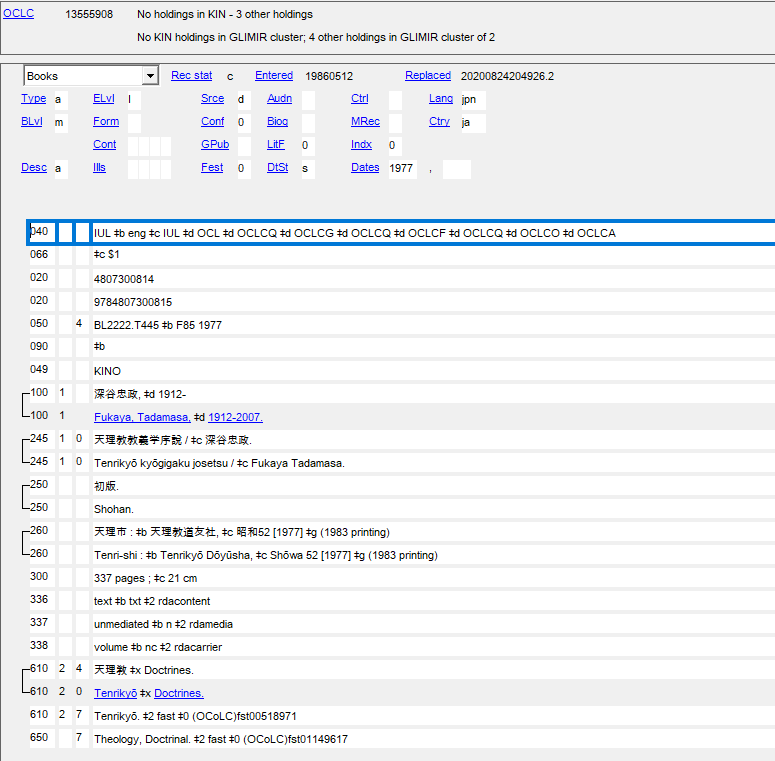
35年経過した最初のCJKレコード
35年の間に米国議会図書館のCJKレコード、RLINのCJK書誌レコード、国立国会図書館のJapan MARC、早稲田大学を始めとする一般ユーザーのMARCレコード、TRCのベンダーレコードがWorldCatに投入された事により、CJKレコード数は飛躍的に増加しました。
2021年1月現在、WorldCat中の日本語資料の書誌レコードは1500万件で言語別6位 (中国語資料が1600万件で5位、韓国/朝鮮語資料が230万件で18位) となっています。
統計: https://www.oclc.org/en/worldcat/inside-worldcat.html
目次へ戻る▲
―OCLC ResearchのブログHanging Togetherより―
次世代メタデータに関する初の英語円卓会議: 相互運用可能な図書館データのクリティカル・マス*を目指して
2021年3月17日 ティティア・ファン・デル・ヴェルフ

このブログ記事は、次世代メタデータに関するOCLCリサーチディスカッションシリーズの一環として、2021年3月2日に開催された第1回英語円卓会議ディスカッションの報告です。
* クリティカル・マス=普及が爆発的に跳ね上がる分岐点
このセッションは、EMEA(ヨーロッパ、中東、アフリカ)のタイムゾーンから幅広く参加できるように計画されました。英国、ポーランド、ギリシャ、レバノン、エジプトから、書誌管理、特殊コレクション、コレクション管理、メタデータ標準、コンピュータサイエンスなどのバックグラウンドを持つ図書館関係者がセッションに参加し、非常に多様で活発なディスカッショングループを形成しました。
各プロジェクトのマッピング
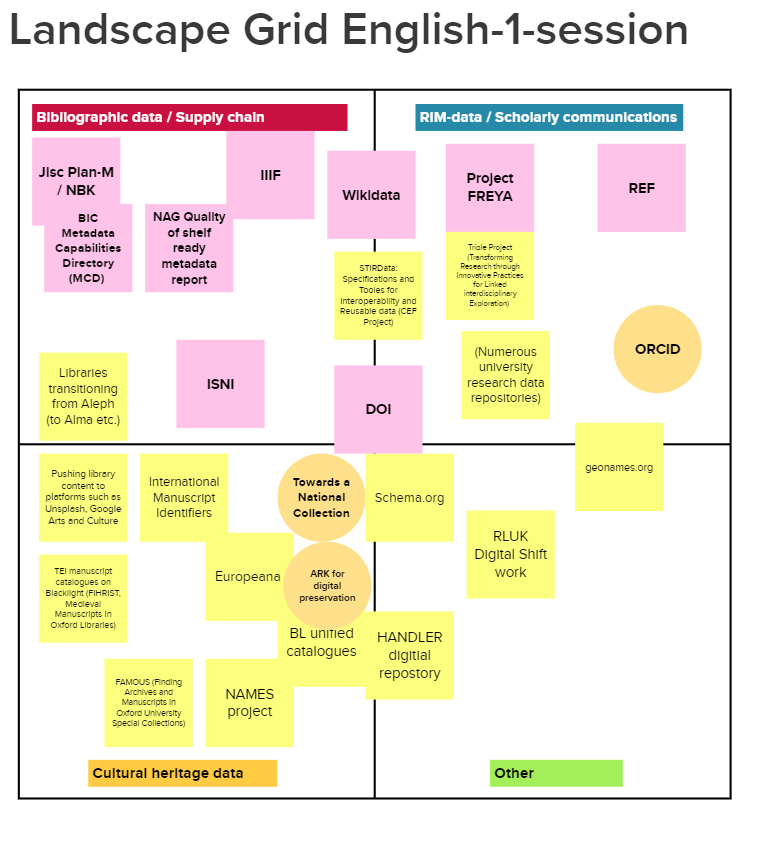 次世代メタデータ・プロジェクト図(英語セッション-1)
次世代メタデータ・プロジェクト図(英語セッション-1)
グループはまず、参加者が認識している次世代メタデータ・プロジェクトを、書誌データ、文化遺産データ、研究情報管理(RIM)データ、そしてそれ以外は「その他」という応用分野を特徴づける2×2のマトリックスにマッピングしました。結果として得られた図では、新たに発生した次世代メタデータ・インフラストラクチャの構成要素が大変分かりやすくなっています。すなわち、あまり知られていない国際標準手稿識別子(ISMI)を含む様々な国際的な識別子のイニシアチブ、3つの異なる応用分野で実装されているスキーマと相互運用性の基準です。この図は、FREYA、TRIPLE、STIRdata、EuropeanaのようなEUが資金を提供しているいくつかの関連プロジェクトを示しています。また、Plan-M(National Bibliographic Knowledgebaseに関連)、Book Industry Communication(BIC)のMetadata Map、British Libraryと出版社が協力してサプライチェーンの上流でISNIを追加する試みなど、サプライチェーン全体でメタデータを合理化するための英国のイニシアチブについても触れたことは注目に値します。最後に、機関固有のプロジェクトとして、FAMOUS(Finding Archives and Manuscripts in Oxford University Special Collections)などが挙げられ、文化遺産の分野ではUKRIが資金提供しているプロジェクトTowards a National Collectionが挙げられました。全体として、機関、国、欧州、国際という非常に異なるスケールで行われている興味深い活動範囲が、これらを超えたイニシアチブの連携について話し合う機会を提供しているのです。
単独で行う事の限界
参加者は、次のレベルのメタデータに移行し、新しい標準や慣行に合わせるための個々の努力と、実際に遭遇した障壁について語りました。ある参加者は、既存のツールやフォーマットを使ったメタデータの構造を変更、PIDやURIの追加、MARCからRDAへの移行を試みたりしていました。また、WikidataやRDFベースのデータモデリング、歴史上の名称や時代、その他の概念のための新しい語彙をリンクトデータ形式で作成するなどの実験を行っているところもありました。
参加者は皆、次世代メタデータの明るい未来に熱中していましたが、同時に、新しいツールを使用する際の課題や急な学習曲線にも強い印象を受けていました。参加者の一人が語ったこの言葉は、様々なウェブベースのツールとその機能の複雑さに対処することに、個人がいかに苦労しているかを示しています。
「Google Arts & Cultureとのプロジェクトで、オンライン上の展示会に追加するアーティストのURIを追加するためにWikidataを使用していますが、時々アーティストのWikidataのURIが見つからないことがあって困っており、どう対処していいか分からないんです。」
相互運用可能な図書館データのクリティカルマスを達成する重要性
参加者は、次世代のメタデータ・インフラストラクチャが、効率化を実現するために必要な規模と相互運用性レベルに到達する日を楽しみにしています。参加者の一人は次のように述べています。「私たちは、大学のすべてのコレクションとすべての研究成果のメタデータを持っていますが、これは日々の仕事の中でもかなりの割合を占めます。それらを次世代のメタデータ・プロセスに移行する方法を考えたいのです。」
彼らは、OCLC Shared Entity Management Infrastructureを歓迎しました。中世のコレクションを扱う出席者の一人にとって、このプロジェクトは非常にエキサイティングなものです。
「私たちは典拠ファイルを手作業で管理しており、一種変わった中世の典拠を通常のNACOファイルに取り込むことができませんでしたが、このプロジェクトは、私たちの仕事のやり方を大きく変えることになるでしょう。私たちのメタデータをパートナー機関と結びつけることができるようになり、中世の写本がもはや閉じたプラットフォーム内のものではなくなることを意味しているのです。」
図書館データの相互運用性向上に向けた一般的な動きの中では、典拠データの有用性を高める試みが中心となっています。ISNIデータベースを米国議会図書館の典拠管理番号とVIAD識別子で充実させ、逆にLC典拠ファイルにVIAF識別子とISNIを入力することは、この取り組みに大きく貢献しています。英国では、この取り組みは大英図書館によって行われています。また、ISBD規格をLRM(Library Records Model)やRDAに対応させるためのIFLAの取り組みや、リンクトデータのエコシステムでIFLA規格を使用できるようにするためのIFLA Namespacesの立ち上げについても言及されました。
アグリゲーションレベルでの相互リンク
参加者は、図書館や文化遺産機関で導入されているメタデータ管理システムやリポジトリは、資料を語彙やシソーラスにリンクさせるための基本的な機能をサポートしていないと指摘しました。この欠点は、この分野の大手が大規模にメタデータを充実させ、リンクされたデータとして公開していることにより、アグリゲーションレベルで満たされつつあることが確認されましたが、出席者の一人が次のように語ったように、この開発はすべての当事者にとって相互に有益であるとは考えられませんでした。
「アグリゲーターやアグリゲーションレベルなどの大規模な企業によるプロジェクトでは、機関から派生したメタデータにリンクやURISを追加することで多くの資金が投入されていますが、付加価値がメタデータを所有する機関に戻っては来ないため、持続可能なものではありません。」
しかし、アグリゲーションは、これまでも、そして今も、異なるサイロにあるデータベースを相互に接続し、結びつけるための基礎となっています。 EUが資金提供するTRIPLEプロジェクトは、この一例として議論されました。TRIPLEプロジェクトは、社会科学と人文科学のコンテンツのアグリゲーターであり、リポジトリや出版社から収集したメタデータをschema.orgベースのデータモデルにマッピングし、多言語化、専門分野固有の語彙やORCIDなどのPIDの使用をサポートしています。また、OpenAIREやEuropeanaといった、欧州の研究分野や文化遺産分野で運営されている類似のプロジェクトとの連携も目指しています。このような分野横断的な相互リンクの利点は明らかですが、グループ内では、アグリゲーターが異種のソースからのデータを重複排除したり、曖昧さを解消したりするのが難しいことも指摘されています。これは、相互リンクがアグリゲーションレベルではなくソースレベルで行われれば回避できる可能性があることを示唆しています。
共有し、労力を重複させない
セッションの最後に、語彙をめぐって小さな議論が交わされました。新しい語彙を作り続けるべきか?すでにあるものを再利用するのはどうか?議論の最後に、参加者の一人が、今あるものを共有し、労力の重複を避け、何よりも自分たちのデータをより多くのコミュニティと結びつける必要があると強調しました。
「これは、データの文脈化や拡充だけではなく、状況を発見し、つながりを持つことでもあります。なぜなら、 私たちは他のコミュニティにも利益をもたらすように構築されている非常に信頼できるデータを持っているからです。」
次世代メタデータに関するOCLC Research Discussion Seriesについて
2021年3月、OCLC Researchは2つのレポートに着目した以下のディスカッションシリーズを行いました。
- “Transitioning to the Next Generation of Metadata” (次世代メタデータへの移行)
- “Transforming Metadata into Linked Data to Improve Digital Collection Discoverability: A CONTENTdm Pilot Project”
(デジタルコレクションの発見性を高めるためのメタデータからリンクトデータへの転換: CONTENTdmパイロットプロジェクト)
円卓会議はヨーロッパの異なる言語で行われ、参加者は自らの経験を共有し、トピック分野への理解を深め、今後の計画に自信を持つことができました。
開会の全体会議では、議論と探求の場が開かれ、テーマとそのトピックが紹介されました。全8回のラウンドテーブルディスカッションの要旨は、OCLC Researchのブログ「Hanging Together」で公開されます。この記事はその最初のものです。
4月13日の閉会の全体セッションでは、各円卓会議での議論を総括します。このウェビナーへの登録はまだ受け付けておりますので、ぜひご参加ください!
当記事の詳細はこちらから>>
目次へ戻る▲
フェイエットビル公共図書館(FPL)がOCLC Wiseを導入
―FPLが目指す「究極の図書館体験」―

アーカンソー州、フェイエットビルのFayetteville Public Library(FPL、フェイエットビル公共図書館)はアメリカの公共図書館向けのコミュニティとの連携を活性化するシステム、OCLC Wiseを導入する契約を締結しました。
CRM(顧客関係管理、Customer Relationship Management)とマーケティングと分析を、貸出と資料購入などのILS(integrated library system)機能と統合することで、Wiseはコミュニティとの提携とコレクション管理を新たなレベルに引き上げます。Wiseは今までの図書館システムと異なり、資料中心ではなく利用者中心で設計されています。図書館がコミュニティの活動の中心へとシフトし続けるのをサポートし、コミュニティに対する影響力を拡大させます。
Fayetteville Public Library (FPL)はFPL2030マスタープランの一部である大規模拡張・リノベーションの最終段階にあります。
OCLC Wiseの導入は、図書館の変容における次の大いなる一歩です。
Fayetteville Public Library常任理事、デイヴィット・ジョンソン(David Johnson)は以下のようにコメントしています。
Fayetteville Public Libraryのゴールは、我々のコミュニティの人々に毎日究極の図書館体験を創り出すことです。なぜかって?それは、皆の幸福を大事にしているからです。我々はOCLCチームとWiseからも同じ信念を感じました。OCLCは我々の最高のサービスを提供する能力を大切にしており、我々とともにベストを尽くすやる気に満ちています。これこそが真のパートナーシップです。
FPLのスタッフが最先端の拡張計画を立てた時、コミュニティのニーズを検討しました。それには、今までになかった職業訓練や料理のスキルや、利用者の中でもとりわけ若者に向けたサービスが含まれていました。スタッフの中には、デンマークのオーフスにある、世界で最も革新的な図書館の一つであるDOKK1を訪問した人もいました。
OCLC副社長のメアリー・サウアー・ゲームズ(Mary Sauer-Games) は以下のように述べています。
FPLは地域のコミュニティに深く根ざし、また大いに提携しています。スタッフはコミュニティの為にベストを尽くしたいと考えており、世界有数の素晴らしい図書館からインスピレーションを得ようとしています。FPLの利用者とのつながりと、将来へのビジョンは、OCLCとWiseのパートナーとしてふさわしいものです。OCLCは、FPLとともに達成できるものを見るのを楽しみにしています。
FPL常任理事のジョンソン氏はまた以下のようにコメントしています。
WiseはFPL利用者のゲームチェンジャーになるでしょう。コミュニティの人々は、美しい施設があるだけでなく、コミュニティにフォーカスしたインフラとテクノロジーも利用できるようにしていることに、感銘を受けるでしょう。我々はニーズを満たすためにシステムとサービスをカスタマイズし、本当に我々のFPLにすることができるのです。
Wiseについてもっと知りたい方は、oc.lc/wiseをご覧下さい。
当記事の詳細はこちらから≫
目次へ戻る▲
OCLC Interlibrary Loan Cost CalculatorでILL料金を算出

OCLC Interlibrary Loan Cost Calculatorとは
OCLC ResearchはOCLC Research Library Partnershipに加盟している機関のスタッフとともに、図書館管理者やスタッフが資料共有にかかるコストをよりよく理解する為のインターネットベースのツールを作成しました。これは図書館同士の協力を促進し、より効率的な運営とより良いサービス提供を目指すOCLC ResearchのUnderstanding the System-wide Libraryという活動の一環です。このインターネットベースのInterlibrary Loan Cost Calculatorによって、以下のことが可能になります。
- 平均的なILLの依頼/受付コストがわかる。
- 自館が他館へ提供する場合の単価を計算できる。
- ILLコストの長期間に渡る変化がわかる。
- 匿名化された他機関の平均ILLコストと自館のコストを比較できる。
- 特定のプロセスをオートメーション化した場合の自館のコストをシュミレートできる。
- 自館のデータをリポートできなかった分野の、自館のコストを推定できる。
背景
世界中の図書館が深刻な予算不足に直面し、多くの図書館の部署が少ないサポートでサービスの質の維持すること、もしくは既存のサービス以上のものを求められています。同時に、利用者の図書館に対する期待は高まっています。ネット上に情報が溢れている時代に、図書館は利用者と資金提供者の双方に、その必要性を継続的に示さねばなりません。必須のサービスが利用者に効率的に、適切なコストで提供されていることを示すことで、これが可能になります。
Interlibrary loan (ILL)はその労働集約性で悪名高く、そのせいで図書館の提供するサービスの中でも最も高価なサービスの一つとなっています。利用者が必要とする資料全てを購入できる図書館は無いので、過去20年間で、ILLは図書館の中心的なサービスとなりました。多くの時間・資金・努力が、ILLプロセスを効率化し、ルーティンリクエストをコンソーシアム内で借りたりオンデマンドで購入したりする等の、よりお金がかからないフルフィルメントとする為に費やされてきました。
もしILLサービスを適切に評価するならば、管理者と資金提供者は、特定の図書館データを測定する現在の基準と同様、コストに関する最新の、詳細な情報にアクセスする必要があります。このような基準はひどく古いものしかなく、直近の総合的なILLコスト研究でも、米国研究図書館協会 (Association of Research Libraries)のマリー・ジャクソン(Mary Jackson) によって行われた2002年のものしかありません。学術図書館員であるラース・レオン(Lars Leon)とナンシー・クレス(Nancy Kress)によって行われた2011年の研究は興味深いデータをもたらしましたが、調査の対象が極めて少ないものでした。ILLコストに関する研究は少ない一方、ILLコストに確実に顕著な影響を与える資料共有の新たな技術と方法が導入されていっていました。
インパクト
時代に合ったフレッシュなコストデータとアップデートされた基準にアクセスできることは、図書館管理者に他館に貸し出すコストをより正確に評価することを可能にし、またILLオペレーションの費用対効果を上げる為の戦略構築をサポートします。
OCLC Interlibrary Loan Cost Calculatorは、図書館が自館のデータを収集し、処理する為のメカニズムと、自館のパフォーマンスを測定する為の基準の両方を提供します。
Interlibrary Loan Cost Calculatorを使ってみよう
OCLC Interlibrary Loan Cost Calculatorを使い始めるにあたっては、以下の手順を参照下さい。
- Quick Start Guideをダウンロードする。
- Quick Start Guide中のチェックリスト“things to know and do”を確認、回答。
- OCLC Interlibrary Loan Cost Calculatorのネット上のインターフェースから貴館を登録する。
- Gather Data spreadsheetをダウンロードする。
- Gather Data spreadsheet reportsから自館のILLコストを確認。
- 貴館のコストデータをOCLCに提出すると、匿名化した他館のILLコストデータのリポートが確認可能となる。
ご質問がある場合は、プロジェクトリーダーのDennis Massieにメールをお送りください。
Interlibrary Loan Cost Calculator ワーキンググループ
Interlibrary Loan Cost Calculatorは、以下のワーキンググループによって開発されました。
- デラウェア大学・Megan Gaffney
- テンプル大学・Justin Hill
- オーストラリア国立図書館・Margarita Moreno
- OCLC Research・Dennis Massie
- 元OCLC Research所属・Ralph Levan
2015年~2020年のベータテスター:
- オーストラリア国立図書館・Margarita Moreno
- デラウェア大学・Megan Gaffney
- テンプル大学・Justin Hill
- カンザス大学・Lars Leon
- オハイオ州立大学・Brian Miller
- シカゴ大学・David Larsen
- カリフォルニア大学ロサンゼルス校・Jenny Lee
- シラキュース大学・Ronald Figueroa
- ブランダイス大学・Matthew Sheehy
- コロラド大学コロラドスプリングス校・Don Pawl
当記事の詳細はこちらから≫
目次へ戻る▲
(紀伊國屋書店 OCLCセンター)
掲載の商品・サービスに関するお申し込み・お問い合わせ先
株式会社紀伊國屋書店 OCLCセンター
電話:03-6910-0514 e-mail:oclc@kinokuniya.co.jp