OCLC News 78号
商品情報をはじめ、OCLCに関する様々な情報をご案内致します。
今号はMARC内のURI活用に関するOCLC Research Library Partnershipの議論、LCが予定するMARCフォーマット変更などの話題をお届けします。
『OCLC News』一覧 >
目次
―OCLC ResearchのブログHanging Togetherより (英語記事翻訳)―
リンキーMARC*のURI利用を促進するために:OCLC Research Library Partnershipの議論概要紹介
*リンクトデータURIで強化されたMARC
2025年3月20日 – アネット・ドルトムント
OCLC Research Library Partnership (OCLC研究図書館パートナーシップ) の Metadata Managers Focus Group (メタデータ管理者フォーカスグループ) は2025年1月に開催され、MARCレコード内に見られるリンクトデータURIの利用、再利用のためのコミュニティ事例を調査しました。参加メンバーは、ディスカバリーシステムおよび統合図書館システムにおいてMARCレコードをリンクトデータによって強化する取り組みを活発にするために現在行っている、あるいは見たことのある作業例を持ち寄るよう求められました。
参加者全員の意見を聴取する会議が3回に分けて行われ、以下の5カ国、25のRLP機関から38人が参加しました。
| British Library |
Rutgers University |
University of Illinois at Urbana-Champaign |
| Cleveland Museum of Art |
Smithsonian Institution |
University of Kansas |
| Cornell University |
Tufts University |
University of Leeds |
| National Gallery of Art |
University of Arizona |
University of Pittsburgh |
| National Library of Australia |
University of Calgary |
University of Southern California |
| National Library of New Zealand |
University of California, Los Angeles |
University of Sydney |
| New York University |
University of California, Riverside |
University of Tennessee, Knoxville |
| Princeton University |
University of Chicago |
Virginia Tech |
| Radboud University |
|
Yale University |
この討議では、次世代メタデータフォーマットへの移行に伴う技術的・社会的課題を検討しました。このブログ記事は、MARCレコード内のURI、AIの利用、図書館メタデータにおけるリンクトデータ導入に関するより一般的な側面など、議論の中で取り上げられた主要なトピックをまとめたものです。
背景
多くの複雑な制度と同様、次世代メタデータへの移行には技術的、社会的な課題があります。過去10年間、メタデータコミュニティは、MARCレコードの「文字列」による記述から、異なる実体 (エンティティ) とその関係を特定するナレッジグラフ構造へと、作業方法を変革する途上にありました。グラフ構造を構築することは、アーチ状の建造物を構築するようなものであり、自立させるためにはすべての部品を所定の位置に配置する必要があるため、私たちは一時的に移行を支援するための足場を配置する必要もありました。この足場の1つが「リンキーMARC=エンティティ情報へのリンクを持つMARC」であり、リンクトデータURIを含むようにMARCフォーマットを拡張したものです。PCC Task Group on URIs in MARC (LC共同目録プログラムの、MARC内URIに関するタスクグループ) から生まれたこのURIを含めることで、BIBFRAMEなどの次世代メタデータフォーマットへの移行が容易になります。

New London Bridge under construction. © The Trustees of the British Museum / CC BY-NC-SA 4.0
私たちは、OCLCのリンクトデータ戦略の一環として、5億以上のWorldCat Entities URIを次の5つの実体タイプでWorldCatレコードに追加しました: Persons (個人)、Organizations (組織)、Places (場所)、Events (出来事)、そしてWorks (著作) です。WorldCat Entities URIによってWorldCatの書誌レコードを充実させることは、MARCデータとリンクトデータの橋渡しとなり、ローカルシステムやワークフローを横断してデータを接続したり、ローカルのディスカバリーシステムなどでリンクトデータの機能を利用したりするための第一歩となります。これらのURIと関連するWorldCat Entitiesデータは、Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC4.0=表示-非営利 4.0) ライセンスの下、私たちのウェブサイトやAPIを通じて、誰でも無料で取得・利用することができます (Meridianのご契約機関には、作成及び編集の権限もあります)。
生成AIが注目を集めているかもしれませんが、リンクトデータもまた、初期のシンボリック人工知能システムの時代に生まれたことを覚えておくことが重要です。セマンティックウェブの開発者は、事実に基づいたメタデータ表示と、推論活動において機械がそれらを解釈するためのメカニズムを提示する必要がありました。現在のAIに関する会話では、この部分を大規模言語モデルによって提供される種類の確率的予測手法にほぼ置き換えています。しかし、過去10年間にコミュニティがリンクトデータに関して行ってきた研究は、依然として重要なものです。最近の論文では、ナレッジグラフ (別名リンクトデータ)、検索エンジン、大規模言語モデルの持つ、特定のユーザーニーズに対応できる強みが強調されています。著者らは、これらの技術を統合することで、より効果的な解決策につながる可能性を示唆し、ユーザーの多様な情報ニーズを考慮することの重要性を訴えています。彼らは、「ユーザーを念頭に置いたこれらの組み合わせと統合に関する研究は、特に実り多いものになるだろう」と考えています。
2025年1月のメタデータ管理者フォーカスグループでの持ち回り発言セッションでは、以下のディスカッション指示に重点が置かれました。
- MARCレコードに追加されるリンクトデータURIで何をしたいですか?
- ディスカバリーシステムおよび統合図書館システムにおいて、MARCレコードへのリンクトデータによる強化を有効にするために何をしていますか?
ディスカッションの結果、メンバーたちは次のような多くの問題に直面していることが明らかになりました。
- リンクトデータは興味深いものであるが、通常の作業や図書館サービスプラットフォーム (LSP) の移行は、実験や選択の余地をほとんど残さない。リンクトデータは、システムを移行するための推進力でもなければ、移行をサポートするものでもない。
- メタデータ管理者は、データの品質および機能とデータソースの信頼性に重きを置いた、シームレスなワークフローの支援ツールを必要としている。
- OCLC URIを使用している出席者はまだ少ないが、リポジトリや文化遺産コレクションにおいてリンクトデータエンティティが必要である事は明白である。
- 生成AIと機械学習は、リンクトデータを作成し改善する機会を提供するが、メタデータ管理者は、いつAIがメタデータのワークフローで使用されたかに対する認識を持続させることについても懸念がある。
- 参加者は、ユーザーがリンクトデータに何を求め、何を必要としているのか、特に生成AIが研究者のデータとの付き合い方を揺るがす中で、理解を深めたいと考えている。
リンクトデータについて考える時間はほとんどない
参加者は皆、MARCにおけるURIの利点について熱心に学んでいましたが、リンクトデータについて考える時間はほとんどなかったというのが大方の共通認識でした。多くの参加者にとって当面の関心事は、新しい図書館サービスプラットフォームの導入、またはその準備で占められていました。後者の場合、通常のワークフローを維持することに加え、新しいプラットフォームへの移行のために既存のメタデータを準備する必要があり、それ以外のことをする余裕はほとんどありません。
この事実から、メタデータにリンクトデータURIが存在することで、将来的にプラットフォームの移行がどのようにスムーズになるのかという重要な疑問が提起されます。
参加者はまた、現時点でリンクトデータはまだ図書館システムのプラットフォームを切り替える原動力にはなっていないことも共有しました。
URI: 経験は少なくとも関心は高い
OCLC URIをシステムやワークフローでどのように使用するか、また、選択したLSP (Library Services Platform) のリンクトデータ機能がどのようにURIを活用するかについて、明確なビジョンを持っている出席者はほとんどいませんでした。 また、OCLCがなぜURIを追加するのか、そしてどのようなライセンス条項の下でこれらを使用することができるのかについて、若干の混乱が見られました。
しかしながら、参加者は機関リポジトリ、データリポジトリ、文化的コレクションのためにリンクトデータエンティティを提供する必要性を指摘し、WorldCat Entitiesがこの分野で有用であると感じていました。個人と組織のエンティティは特に関心が高く、件名や分類のURIはそれほど関心が高くありませんでした。
現在のリンクトデータツールはまだ納得のいくものではない
さらに最新のLSPは、MARCでコーディングされたURIを新しい目録作成ワークフローやユーザー向けのディスカバリー機能で使用する機会となり得ます。しかし、何人かの参加者は、現在利用可能なリンクトデータ機能で作業することの難しさを指摘しました。彼らは、シームレスなツールを求めていますが、実運用の準備が整っていない分断された環境しか見つけられていません。
例えば、URIを使用して特定のエンティティに関する情報を展開し、その情報をナレッジカードでユーザーに公開することができます。このような機能を持つシステムでは、簡単に設定を変更することができます。この機能を検討している出席者によると、このような機能を正確で有用なものにするためには、やはりメタデータの品質が重要な部分を占めるとのことです。事例として、Personカードが間違ったエンティティを指していたり、正しくない情報を含んでいたりすることがありました。これらはウィキデータなどの外部ソースに依存している可能性があるため、ソースを更新するには技術と知識が必要です。それでも、その変更がローカル環境に伝わり、エンドユーザーに見えるようになるまでには時間がかかるかもしれません。
オープンソースのディスカバリーレイヤーを採用している組織では、リンクトデータURIを活用するワークフローやインターフェースを開発するために、ローカルリソースを割く必要があるかもしれません。
リンクトデータ機能が利用可能であっても、基盤となるメタデータの一貫性が保たれていない場合、ユーザーは探しているものを見つけるために複数のサイロの間を移動する必要があるかもしれません。よくある例として、同一人物について単行本と論文レベルの出版物の両方を横断的に検索できるとは限りません。ORCIDとISNIの永続的識別子が利用可能な場合でも、それらが単一のエンティティに統合されていない場合があります。書誌資料だけでなく、美術品や特殊コレクションにまで範囲を広げても、実体情報が統一されていない場合には同様の課題が残ります。
このようにリンクトデータが現在のシステム、ツール、ワークフローと統合されていないことが、既存のリンクトデータ機能やソースに対する信頼の欠如と並んで、採用の障壁となっています。
参加者はまた、自分たちの仕事に役立てるために、ユーザーのニーズをよりよく理解することを望んでいます。どの参加者も、ユーザーがどのように実体情報を利用したり、閲覧したりするかについて、体系的な研究を積極的に行っておらず、この分野でのユーザー研究が必要であるという点で意見が一致していました。さらに、現在のディスカバリー体験で役立つような、ユーザーについてこれまで学んできた多くのことが、対話型AIチャットボットへのアクセスによって揺らいでいます。私たちは、このトピックを将来のセッションで探求するものとして位置づけました。
AIが生成するメタデータの可能性と懸念
メタデータ管理者の間で引き続き懸念されているのは、将来の目録作成とメタデータのワークフローにおいてAIが果たす役割です。今回の議論の中で、メタデータ管理者は、メタデータレコードの出自について他者 (目録作成者、利用者など) に知らせる最善の方法を検討することも含め、AIの利点を責任を持って活用する方法について理解を深めたいと考えていました。
AIの可能性と品質とのバランス
新たなAI目録作成支援ツールにアクセスできる参加者は、これらのツールが、その後で人間主体のワークフローにより補強される簡略レコードの足掛かりにどのように役立つかを共有しました。特に、一般的なコレクションと特殊コレクションの両方が多大な滞貨に直面していることを考えると (これについては、以前の議論「Keeping up with next-generation metadata for special collections and archives」 (アーカイブと特殊コレクションにおける次世代メタデータへの対応) を参照)、印刷物から情報を転記する最初の作業をAIアシスタントに任せることは、時間の節約になるでしょう。このようなアシスタントが十分な品質のレコードを作成すると信じられるかどうかは、依然として研究対象であり、関心のある分野である事に変わりありません。
一貫したAIデータ来歴表示の必要性
AIの利用について話をする中で浮かび上がってきた重要な疑問は、どのようにデータ来歴表示を行っているのか、またどの程度の粒度でデータ来歴表示が必要なのかということです。前述のエージェントや他のAI主導の初期のMARCワークフローでは、記述の作成にAIが使用されたことを示すために、588 記述のソース (Source of Description) 注記を使用することでコンセンサスが得られています。
リンキーMARCでは、テキストで記載されたラベルと一緒にURIを記録することができるため、これらのURIをデータ来歴の目安とすることも可能です。参加者は、LC/NACO 典拠ファイルのレコードには、その典拠がどのように確定したかについての多くの情報が含まれており、目録作成者がその典拠を信頼するかどうかの判断を下すために利用できる、人間が読める情報を提供していると指摘しました。この種の信頼は、id.loc.gov のリンクトデータ実体および URI に容易に拡張することができます。では、目録担当者の専門的な判断を再現する方法で、特にその判断がAIエージェントによって行われた場合、異なるリンクトデータソースに対する信頼をどのように表現できるでしょうか。異なるURIを使用するエンティティの繰り返しが提示された場合、私たちはその中からどのように選択すればよいのでしょうか?ある参加者が示唆したように、この質問に対する答えは一つではないかもしれません。むしろ、環境やユースケースごとに異なる信頼レベルを表現するアプリケーションプロファイルを開発する必要があるかもしれません。
最終的な考察
この記事は、リンクトデータのエコシステムを構築する際に、新しく出現するデータ構造とワークフローをサポートするための足場が必要であるという話から始まりました。 大規模言語モデルを搭載したAIは、組織を新しいプラットフォームへと導くだけでなく、ディスカバリーや利用者のニーズを満たすことについての考え方を根底から変えようとしています。Google検索がOPACの概念を覆し、近代的なディスカバリーレイヤーの時代へと導いたように、AIは我々にリンクトデータで何をするかを再考させようとしています。その一例が、米国議会図書館の 「Modern MARC」という試みで、識別子を追加し、よりナレッジグラフへの変換に適したリンクトデータのモデルを採用することで、「リンキー」MARCをさらに拡張するものです。ナレッジグラフ構造は、ユーザーインターフェースにナレッジカードを表示するだけでなく、ループ内の人間が信頼するメタデータによって大規模言語モデルの幻覚を最小限に抑えることで、本来の使命を果たすことができます。
このブログ記事の執筆は共同作業によって行われました。特に同僚のレベッカ・ブライアント、デイビッド・ハイマン、エリカ・メルコ、マーシー・プロカッチーニ、メリリー・プロフィット、チェラ・ウェーバーに感謝いたします。
目次へ戻る▲
原文はこちらから>>
―OCLC 事業部解説―
米国議会図書館の考える「現代の」MARCとは?
ここでは、ひとつ前の記事で触れられていた米国議会図書館 (Library of Congress=LC) の「Modern MARC」についてご紹介し、今後の書誌レコードがどのように進化していくかを探っていきます。
MARCレコードからリンクトデータの構築を可能にするため、RDAに合わせて入力規則の変更やMARC拡張の試みが行われる中、米国議会図書館が今後の変更予定を説明する「“Modern” MARC」と題するドキュメントを公開しています。
この文書では、今までに行われた変更と今後行われる予定の変更について説明されています。それぞれに補足を交えて見ていきましょう。
RDAに伴うMARCコード化データ
RDAによって導入された主な変更の1つは、既存の固定長フィールドのコード化されたデータよりも、新しく設けられたフィールドのテキストデータが優先されるようになったことです。その例は、MARC内のコード化情報が入力されるフィールド、特に007と006フィールドで説明することができます。MARCでTag 3XXの範囲にはテキスト情報として、007フィールドのコード化情報の多くをテキスト形式で冗長的に伝えるために設けられました。
例えば、007では
007 kd#bc| (静止画像-図画–白黒-ボール紙またはイラストレーションボード)
の情報は以下の340と重複しています (技法部分が少し違いますが)。
340 ## $a cardboard $d collotype $g black and white
(ボール紙をベース素材とするコロタイプによる白黒印刷物)
目録担当者は現在、この新しい3XXフィールドを使用するよう訓練されていますが、同時に同じ意味を持つ情報を固定長フィールドに記録する以前の慣行も続いています。これは、現在のMARCレコードでの必要性と将来のデータフォーマット移行準備用という意味がありますが、重複した冗長なデータを生み出すだけでなく、目録担当者の側にも、おそらくは冗長な、余分な労力を要求することになります。
(コード化に対する) テキストによる記述に加え、RDAはデータ中に識別子を使用することを強く推奨しており、それらはリンクトデータにとって不可欠な要素です。これらの識別子の多くは統一資源識別子 (Uniform Resource Identifiers)、すなわちURIの形をとっており、これは一般的にウェブアドレス、すなわちURLのように見えます (し、実際そうです)。例えば、以下のようなものです。
http://id.loc.gov/vocabulary/mmaterial/crd
URI、あるいは一般に識別子の使用は、レコードに付加的なデータを導入するだけでなく、MARCの構成変更を余儀なくします。以前 (上記の340の例) は、1つのフィールドが複数の値に使われていましたが、識別子と明確に関連付けるためには、識別子の数だけフィールドを繰り返さなければなりません。
340 ## $a cardboard $0 http://id.loc.gov/vocabulary/mmaterial/crd
340 ## $d collotype $0 http://id.loc.gov/vocabulary/mproduction/collo
340 ## $g black and white $0 http://id.loc.gov/vocabulary/mcolor/blw
このようなフィールドの繰り返しは、今日でも URI と値を関連付けるために行われることがありますが、今後曖昧さを避けるために LC レコードではより一貫して使用されるようになります。
データ内容の重複
上述の通り、007にコード化された形で格納されているデータのほとんどは、RDAが採用された際にそのデータのために設けられた3XXフィールドに格納されます。しかし、移行期間中は007の最初の2つの文字位置 (007/0, 007/1) は、RDAのために新設されたフィールド337および338の情報と重複するにもかかわらず、レコードに引き続き記録されます。
書誌レコードの ISBD 区切り記号の使用を減らし、ISBD 区切り記号の適用に柔軟性を持たせるという共同目録プログラム (PCC) の方針に従い、レコードは引き続き、245と264のフィールドにのみ完全なISBD区切り記号を保持し、250と490には部分的なISBD 区切り記号を保持しますが、書誌レコードの他の部分には最小限のISBD区切り記号を使用する事になります。MARC記述形式(LDR/18)は、「i」(ISBD句読点を含む)とコード化されます。目録アプリケーションでの表示は以下のようになります。
非ラテン文字データの扱い
まず、MARC 21フォーマットで非ラテン文字データをどう扱っているかをおさらいします。
LCのMARC書誌レコードは、使用する非ラテン文字を将来的に拡大する予定です。それらは以下のような特徴を持つことになります。
- 130, 240, 700, 710, 711, 730などのアクセスポイントは、非ラテン文字データのローマ字翻字形を保持し続け、非ラテン文字データ (漢字などのバナキュラー) を持つ880フィールドが対になる。
- 通常、ローマ字翻字形は245, 250, 264, 490のレギュラーフィールドに与えられ、対になる880フィールドには非ラテン文字データが含まれる。
- 非ラテン文字データのローマ字翻字は、現在と同様、レギュラーフィールド (880フィールドではない) で行われる。
- 翻字は現在と同様、ALA-LCの翻字表に従う。
- 880フィールドは、サブフィールド$6の手法を用いて、通常の方法で翻字フィールドにリンクされる。
- ラテン文字フィールドと対になっていない非ラテン文字データは、880フィールドではなく、レギュラーフィールドに入る。
これは主に5XXフィールドの範囲で発生する。現在のMARCでは、ラテン文字と対になっていない非ラテン文字は880フィールドにあり、そのデータがラテン文字フィールドと対になっていないことを示す数字 (00) が連番部分に表示されている。
ここで大きな変更があります。最後の「ラテン文字フィールドと対になっていない非ラテン文字データは、880フィールドではなく、レギュラーフィールドに入る。」です。
これを読んで、Record ManagerやConnexionをお使いの方は不思議に思うかもしれません。
試しに現在のデータの状態を確認してみましょう。例に挙げたのは国立国会図書館 (OCLCシンボルNHN) がWorldCatに搭載している書誌レコードで、目録規則は日本目録規則2018年版 (NCR2018)、目録言語は日本語です (040フィールド参照)。
Connexion clientを通じてバナキュラーフィールドとレギュラーフィールドを見ると
タイトルのバナキュラー形 (非ラテン文字データ) とローマ字ヨミ (ラテン文字データ) は同じフィールドでペアになって見えます。

一方、バナキュラー形のみで存在している参考文献注記は以下のように504のフィールドに単独で存在しているように見えます。

これがこの書誌レコードの真実の姿ではありません。目録用アプリケーションでは、利用する人がインターフェース上見やすいように変換して見せているからです。
この書誌レコードをエクスポートしてMARCエディターで見てみましょう (例はUnicode表示)。
ここでもMAchine Readable Catalog を人が見やすいように表示している事に変わりないですが、フィールドやサブフィールドは本当の値を見せているからです。
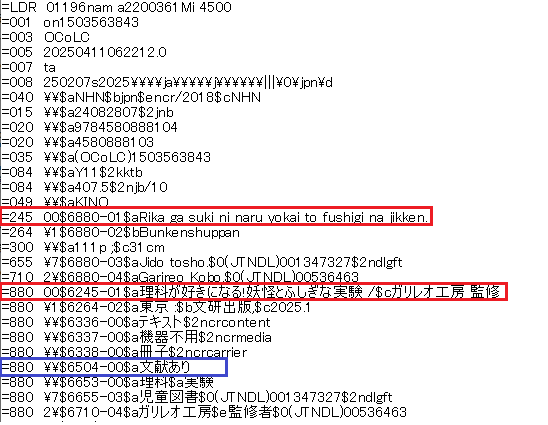
ローマ字ヨミはMARC 21のレギュラーフィールド (Tag 245, 264, 700など)、バナキュラーはTag 880でお互いにサブフィールド$6に相手方のフィールドと順序を表す連番を付けてリンクさせています (赤で囲った部分)。
バナキュラーフィールド単独で存在し、ローマ字ヨミを伴わない場合でも同様にTag 880に入っています。相手方が存在しないもの (青で囲った部分) は連番部分が「00」となっているのが分かりますね。
5XXの注記フィールドだけではなく、NCR 2018で規定されている表現種別 (336)、機器種別 (337)、キャリア種別 (338) もローマ字ヨミを伴わないため、目録用アプリケーションを通さないMARCレコード自体をみると880に入っています。
これが、将来は変更され、ローマ字ヨミフィールドを伴わないバナキュラーフィールドはMARCのレギュラーフィールド (上記の例では504や336-338) に直接入るようになるという事です。
出版等の表示
RDAに合わせて、制作、出版、発売、製作の表示を個別に扱えるようにするため、MARCに新たな出版等の情報を記述するフィールド264が設けられました。2011年まで260フィールドは繰り返し使用ができなかったため、出版等の記述は長年にわたり1つのMARC フィールド260の記述にまとめられていました。LCは、この出版等に関する記述の分離に基づいて変更を進める予定です。1つの260フィールドに複数の出版等の記述を含んでいた以前のMARCレコードは、264フィールドを使用し、個々の出版等の表示に対して1つの264を使用するよう分割します。
以前の慣行:
260 ## $a London, England : $b Penguin Books ; $a New York, N.Y. : $b Penguin Putnam, $c 1999.
変換後の記述:
264 #1 $a London, England : $b Penguin Books.
264 #1 $a New York, N.Y. : $b Penguin Putnam, $c 1999.
シリーズ表示の転記
MARCフィールド490は、シリーズ表示の転記を記録するために使用されます。490 $aは、サブシリーズを持つメインシリーズやシリーズが並列タイトルを持つ場合に繰り返し使用できます。以前のMARCレコードは1つの490フィールドに複数のシリーズ表示が含まれていましたが、曖昧さをなくすため、シリーズ表示1つに対して1つの490フィールドになるよう分割します。メインシリーズタイトルとサブシリーズタイトル、またはシリーズタイトルと並列シリーズタイトルの場合がこれに該当します。
以前の慣行:
490 1#$aDepartment of State publication ;$v7846.$aDepartment and Foreign Service series ;$v128
変換後の記述:
490 1#$aDepartment of State publication ;$v7846.
490 1#$aDepartment and Foreign Service series ;$v128
それぞれのシリーズタイトルの関係性は490を見ただけでは分からなくなるようです。もちろん、アクセスポイントとしてのシリーズは800-830に典拠形が入ります。
LCSHがさらにリンクトデータ準拠に
米国議会図書館件名標目 (LCSH) のジャンル/形式細目に関する方針は、多くのLCSH標目+ジャンル/形式細目の文字列について、対応する包括的なURIが存在しないという理由で、リンクトデータに準拠していません。BIBFRAMEへの移行は、LCSHをよりリンクトデータに準拠させる機会です。Modern MARCのレコードは、必ずしもLCSHに形式細目 ($v) を含まないでしょう。LCSH形式細目の代わりに、資料のジャンルや表現形式を識別するため、米国議会図書館ジャンル/形式用語 (LCGFT) のファセット用語が655フィールドに割り当てられます。
尚、以上の説明中、今後の変更点に関して米国議会図書館はまだ具体的なスケジュールを提示してはいません。
目次へ戻る▲
「”Modern” MARC」原文はこちらから>>
関連資料: Williamschen, Jodi. 2025. Modern MARC : Library of Congress BIBFRAME Update Forum, January 27, 2025 (パワーポイント資料)
―公共図書館のスタッフが集い、充実した活気ある図書館づくりに必要な知識、スキル、支援を提供する場WebJunction®から (英語記事翻訳)―
食べられる本のイベントで美味しい本を味わう
2025年3月17日 – ディー・ミッシェル

Twilight, photo courtesy New Durham Public Library (NH) on Facebook
図書館に行って本を食べる!これが、創造性とコミュニティ活動と食の楽しみを融合させたエディブルブック (食べられる本) イベントの発想です。エディブルブックの催しは、特定のタイトルや総称的な「本」を食べ物で表現する国際的なイベントです。1999年にカリフォルニア州サンタモニカで始まったもので、イベントは通常、4月1日に生まれたフランスの美食家、ジャン=アンテルム・ブリヤ=サヴァラン(1755-1826)にちなんで4月の初めに開催されます。
公共図書館では、メイン州ボウドイナム、マサチューセッツ州ノーサンプトン、コネチカット州グロトン、フロリダ州マイアミ・デイド郡、オハイオ州カートランド、ネブラスカ州カーニーなど、広範囲の様々な町でエディブルブックイベントを開催しています。
審査員が独創的な賞のカテゴリーを考案し、表彰式の後、参加者全員で作品を実食します。資金調達にしたいのであれば、参加費や応募料金を徴収することもできます。しかし、エディブルブックイベントを成功させるために金銭のやり取りは必要ありません。また、図書館が食べ物の持ち込みを禁止している場合は、近くの会場で開催することもできます。
どのエディブルブックも、甲乙つけがたく驚きと感動に満ちています。応募作品は食用に適したもので、作り手の本に対する解釈、物語のテーマ、特定のタイトル、あるいは総称的な 「本」を表現しています。子供たちは好きな絵本をモチーフにケーキを焼いたりデコレーションしたりしますが、大人は抽象的で複雑な手法を使うこともあります。

The Wonderful Wizard of Oz and Breakfast in the Rainforest: A Visit with Mountain Gorillas, Northampton, MA. Photo by Nate Jasper

Flags of our Fathers; Go, Dog, Go; and The World Atlas, Northampton, MA. Photo by Nate Jasper
フライドポテトで作られた「ロード・オブ・ザ・フライズ (「Lord of the Flies=蠅の王」のもじり」、野菜とディップとライ麦パンで作られた「ライ麦畑でつかまえて」、スイカを丸ごと彫って作られた地球儀で表現された世界地図、カップケーキで作られた「はらぺこあおむし」、緑色の卵とハムで作られたドクター・スースの「グリーンエッグスアンドハム」、緑色のアイスクリームコーン、半透明の緑色のキャンディ、黄色のペッツキャンディー風レンガで作られた「オズの魔法使い」の幻想的な「エメラルドシティ」などがあります。たいてい1人ないし2人の単位の子供や大人が応募するものですが、更生訓練施設や小学校のグループが協力して、素晴らしい食べられる作品を作る事もあります。
エディブルブックイベントを主催することは、創造性、コミュニティ、そして物語への共通の愛を融合させる楽しく創意あふれる方法です。古典文学を巧みに解釈した料理を作るもよし、本好きの仲間が集まる口実のためだけでもよし、このイベントは誰もが楽しめるものです。何より、図書館のスペースや予算、参加者に合わせてアレンジできるのが魅力です。あなたの図書館でも、この美味しい伝統行事を取り入れてみませんか?
ある者は作る。 またある者は鑑賞する。 そして全員が食べる!
目次へ戻る▲
原文はこちらから>>
(OCLC事業部)
掲載の商品・サービスに関するお申し込み・お問い合わせ先
株式会社紀伊國屋書店 OCLC事業部
電話:03-6910-0514 e-mail:oclc@kinokuniya.co.jp