OCLC News 第70号
商品情報をはじめ、OCLCに関する様々な情報をご案内するOCLC News
今回は2023図書館総合展で開催されるOCLCフォーラムの特集号です

目次
今回で25回目を迎える図書館総合展は2023年10月24-25日、4年ぶりにパシフィコ横浜で会場開催されます。弊社は、10月25日 (水)にOCLC WorldCatをクローズアップするフォーラム「OCLC WorldCatでつくる図書館の未来: 目録データの国際標準がつなぐ日本と世界」を開催いたします。

OCLC Newsではこのフォーラムをよりよく理解するための副読本としてご参照いただけるよう、OCLC WorldCatの基礎知識、WorldCatをベースとした様々なサービスや今後の展開についての情報を皆様にご提供いたします。
WorldCatとは
WorldCatは、OCLCが運営する、参加図書館の総合目録で、図書館の所蔵資料に関する情報を集めた、世界で最も包括的な書誌情報データベースです。以下は2023年7月現在の書誌・所蔵レコード数です。
書誌レコード数: 548,698,832件
所蔵レコード数: 3,336,254,047件
(WorldCat.orgは、WorldCatデータベースの内容と人気データベースからの論文引用が検索できるウェブサイトであり、今回は取り上げていません。)
WorldCat内の書誌レコードで記述される資料の言語は2023年5月現在で490言語、また多い順に10位までの言語は以下のようになっています。
| 順位 |
言語名 |
割合 |
書誌件数 |
| 1 |
英語 |
39% |
2億1,500万件 |
| 2 |
ドイツ語 |
15% |
6,500万件 |
| 3 |
フランス語 |
9% |
4,800万件 |
| 4 |
スペイン語 |
5% |
1,800万件 |
| 5 |
中国語 |
3% |
1,750万件 |
| 6 |
イタリア語 |
3% |
1,400万件 |
| 7 |
日本語 |
2% |
1,300万件 |
| 8 |
ポーランド語 |
1% |
800万件 |
| 9 |
オランダ語 |
1% |
780万件 |
| 10 |
ロシア語 |
1% |
770万件 |
表1: WorldCat内データのテキスト言語トップ10
非ローマ字言語資料の割合は2023年7月現在で48種類、日本語を含むCJK文字資料のデータが非ローマ字言語の資料では圧倒的に多くなっています。
| 順位 |
文字の種類 |
割合 |
件数 |
| 1 |
CJK (日中韓) |
71.9% |
3,200万件 |
| 2 |
キリル文字 |
8.8% |
390万件 |
| 3 |
アラビア文字 |
7.7% |
340万件 |
| 4 |
ヘブライ文字 |
6.8% |
300万件 |
| 5 |
タイ文字 |
2.7% |
120万件 |
| 6 |
ギリシャ文字 |
1.3% |
599,000件 |
| 7 |
タミル文字 |
0.2% |
93,000件 |
| 8 |
アルメニア文字 |
0.1% |
67,000件 |
| 9 |
デーヴァナーガリー文字 |
0.09% |
44,700件 |
| 10 |
ラオ文字 |
0.02% |
|
表2: WorldCatにおける非ローマ字言語資料データトップ10とその割合
WorldCatのデータ
2010年以降の出版物に対する書誌レコード作成館の割合 (2023年4月現在)は以下のように参加館作成が60%強、アメリカ議会図書館とその他の国立図書館作成データが25%ほどとなっています。
| 書誌レコード作成館 |
割合 |
| OCLCと参加図書館 |
61.57% |
| LC以外の国立図書館 |
22.74% |
| ベンダー/出版社 |
13.29% |
| アメリカ議会図書館 (LC) |
2.40% |
表3: WorldCat内データの作成館種類別割合
WorldCatの書誌レコードはMARC 21フォーマット準拠ですが、MARC 21は資料の種類により8つのフォーマットに細分化され、それぞれのフォーマット特有の項目を持っています。各フォーマットで表現される資料種別は以下の通りです。
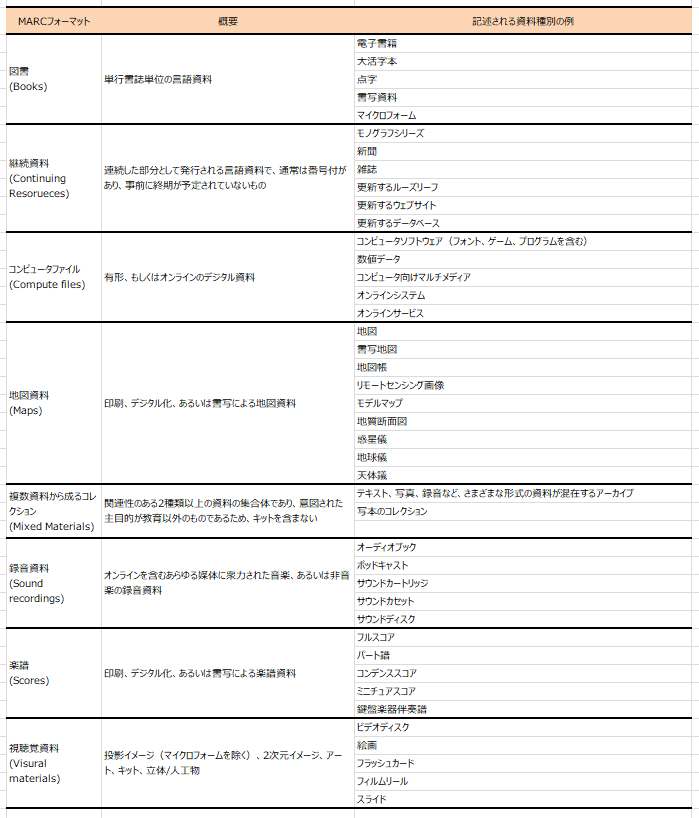
表4: MARC 21の各フォーマットで記述される資料種別
WorldCatの書誌、所蔵レコードを使ったOCLCのサービス
豊富なデータは目録作業に利用されるだけではありません。資料発見、相互貸借を中心としたフルフィルメント、さらにその先にも用途は広がっています。
Cataloging and Metadata
現在、WorldShare® Record Manager、Connexion® clientという2種類のアプリケーションでWorldCatの書誌レコードにアクセスし、自館の目録作成に利用する事ができます。自館の所蔵を登録すればOCLCのその他のサービスで活用できます。
WorldShare® Collection Manager
電子媒体と紙媒体両方のメタデータをコレクションレベルで管理するツールです。
FirstSearch®
WorldCatのデータだけでなく、16,000タイトル以上の雑誌の目次情報や記事情報をいち早く検索できる 「ArticleFirst」など様々な種類のデータベースが持つ情報をFirstSearchプラットフォーム上で検索できる情報検索サービスです。
WorldShare® Interlibrary Loan
WorldCat上のおよそ4億件の書誌レコードを対象に、所蔵機関を確認、56か国10,000館以上の図書館に対して資料の現物貸借・文献複写を依頼/受付できるサービスです。
WorldCat® Discovery
WorldCatのデータはもちろん、ご契約のオンライン資料や記事単位のデータを探せるディスカバリーサービスです。
Shared Printプログラム (日本未紹介) … OCLC Newsの関連記事
利用の少なくなった冊子体資料について複数図書館での重複をなくし、共同保存、共同利用を進めるためのプラットフォームとしてWorldCatを利用、自館の所蔵情報に誓約内容(いつまで保存するか等) を登録するプログラムです
GreenGlass® (日本未紹介) … OCLC Newsの関連記事
図書館グループが冊子体のコレクション管理における除籍や移管等に対して、重複、主題の分散、利用頻度に関して視覚化とモデリングツールを使ったサポートを提供し、根拠に基づいた決定を下せるようにします。
次世代のWorldCatとは
今後、MARCレコードから実体 (Entity) をリンクトデータと識別子で構成したメタデータで表現する形式へと目録作業は変化していくでしょう*。
OCLCの研究部門 (OCLC Research) では次世代メタデータについて先進的な研究やメンバー図書館参加の実験的な試みを進めています。WorldCatに含まれるデータは新しい形式のメタデータへ容易に移行、次世代へと引き継がれていきます。
*次世代のメタデータについてはOCLC Researchのレポート、ウェビナー等をご参照ください。
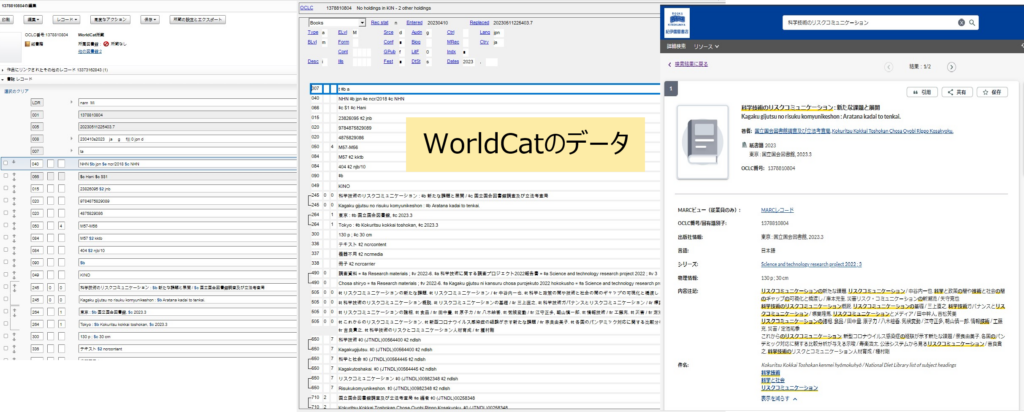
色々なアプリケーションで見る同じWorldCatレコード(左からRecord Manager, Connexion client, WorldCat Discovery)
今回の図書館総合展ではWorldCatを自館の業務にご活用中の早稲田大学様、慶應義塾大学様、国際日本文化研究センターの江上敏哲様にご登壇いただき、その経験をご講演いただきます。また、OCLC CEOのSkip Prichardからも日本の図書館の皆様へメッセージをお届けいたします。是非、この機会にパシフィコ横浜へお越しください。(リンクは過去のOCLC News、またはOCLC 出版物に掲載の関連記事)
目次へ戻る▲
―OCLC ResearchのブログHanging Togetherより―
機械学習とWorldCat:目録作成と発見のための書誌レコード重複排除
メリリー・プロフィット
このブログ記事は、OCLCデータサイエンス&分析部門上級技術部長、ジェニー・トーブスによって執筆されました。
何千もの提供元からのデータを集約するシステムには、重複*を減らし、正確なデータが残るようにする洗練された工程が必要です。WorldCatはそういったシステムの一つであり、世界中の図書館から毎日何千もの書誌レコードを受け取っています。手作業であれ自動化されているものであれ、1980年代初頭から書誌レコードに対して何らかの重複排除が行われてきました。OCLC のスタッフや、参加館によるデータ統合プログラム (Member Merge Program) に参加している機関の図書館員によって、手作業によるデータ調査が毎日行われていますが、WorldCat データのほとんどの重複排除は、自動化された重複排除プログラムによるものです。1990年代に導入された自動化プロセスは、重複検出と解決(Duplicate Detection and Resolution = DDR)として知られ、成長してきました。現在、月平均11,000件の書誌レコードが手作業で削除され、100万件が自動処理によって削除されています。さらに、新たに取り込まれた書誌レコードを毎月数百万件、既存のWorldCatレコードに統合しています。
目録規則や目録作成の指導内容は数十年の間に何度も進化してきました。これは、重複排除に使用される規則が、最新かつ最高のものに追いつくために、継続的に進化しなければならないということです。OCLCのスタッフは統合処理が行われる限りは、特に不適切な統合や統合処理から漏れたものなど、処理を改善するために結果を注意深く検証し、それに応じて規則に基づいてシステムを更新してきました。これは多くの場合うまく機能していますが、重複したレコードがWorldCatに入ることは依然としてあり、目録担当者、研究者、図書館スタッフのワークフローに影響を及ぼしています。
幸いなことに、テクノロジーは進歩し続けており、自動化された処理に新しいテクノロジーを取り入れることが可能です。ここ最近では、数十年前からあった機械学習(ML)が主流になりつつあります。優秀な社会人による機械学習の定義は「…明示的にプログラムされることなく、予測や決定を行うために、学習用データとして知られるサンプルデータに基づいてモデルを構築するアルゴリズム」である、というものです。(このウィキペディアの記事は、機械学習の一般的な理解と、それが人工知能やAIのような他の分野にどのように適用されるのかについての確固たる根拠を示しています)。機械学習と我々の現在の手法との決定的な違いは、この定義の最後の部分にある「明示的にプログラムされることなく」です。機械学習は学習データ(正しい答えでラベル付けされたデータ)を見て、そのデータがなぜそのようにラベル付けされているのかを理解します。そして「学習」したことを新しいデータセットに適用し、機械学習は正確にラベル付けされたと思われる割合を提示します。
2022年初頭、OCLCのデータサイエンスチームは、機械学習を使用してWorldCat内の重複レコードを検出するという課題を与えられました。もし機械学習がDDR以上の重複を検出することができれば、OCLCの標準的な解決プロセスにより重複レコードは削除され、適切なレコードは保持されることが保証されます。様々な機械学習アルゴリズムが調査されましたが、より大きな壁は、選択されたアルゴリズムを実行するためのトレーニングデータを集めることでした。データサイエンスチームは、データ品質管理チームに働きかけてデータのセットを探したところ、データ品質管理チームは、初期検証のための情報を提供することができました。さらに私たちは、手作業で行っている重複排除と同じように、メンバー図書館にもこの処理に参加してもらおうと考えました。これは、データラベリングとして知られる実習の発端であり、機械学習モデルが重複と考えるレコードのペアをチェックして、それらにラベルを付けるよう、メンバー図書館(つまり、目録作成の専門家)に依頼するものでした。
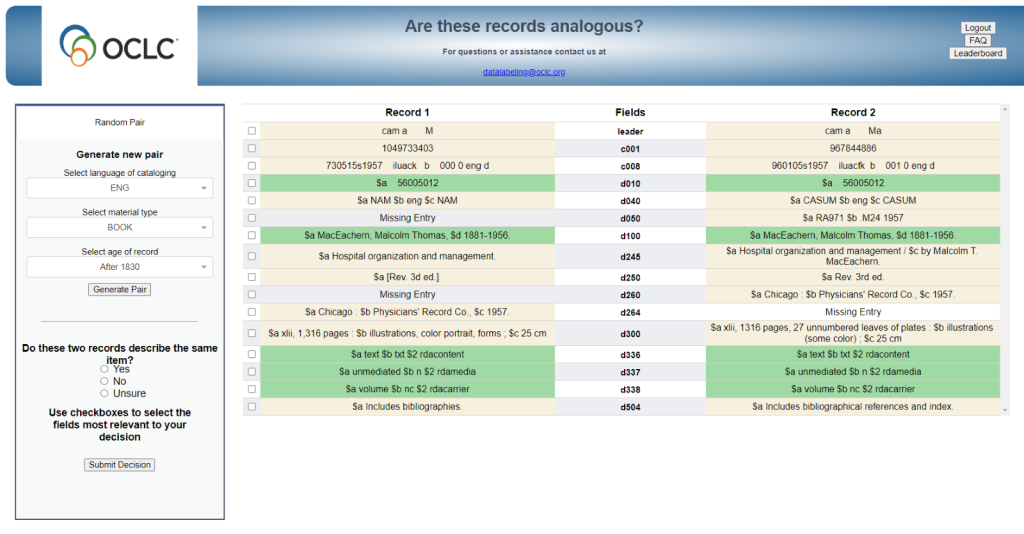
重複分析中の2つの書誌レコードと選択オプションを示すデータラベリング実習用ユーザーインターフェース
2022年の中頃には、データ品質管理チームによる継続的な分析と助言を受けながら、機械学習モデルの改善が行われました。データラベリング演習のためのユーザーインターフェースも構築され、テストされました。このインターフェースでは、重複が疑われる書誌レコードのペアを検索することができます。ユーザーは、目録言語、資料タイプ、およびレコード年代**を選択することによって、重複疑いペアを生成することができます。これらの項目が選択されると、2つの書誌レコードが画面に表示されます。黄色は2つのフィールドに違いがあることを意味し、緑はフィールドが完全に同じであることを意味します。次にユーザーは、これら2つのレコードが同じことを記述しているかどうかを尋ねられ、「はい」、「いいえ」、または「わからない」と答えることができます。また、各フィールドの横にあるチェックボックスにチェックを入れて、何を判断材料にしたかを示すことも可能です。全体として、このツールは2万組のペアを用意し、それぞれのペアを異なる評価者が3回チェックすることを目標にしました。
参加館によるデータ統合プログラム (Member Merge Program) の参加者へは、11月までにこのツールが紹介され、12月初旬にはすべてのOCLCメンバーに提供さ れました。このツールは2023年4月中旬まで公開され、この時点までに34,000組強の重複疑いレコードがチェックされました。各ペアのチェック回数は3件に満たないものの、機械学習モデルをトレーニングするためのデータは十分に収集されました。複数回チェックを受けたペアの95%以上は、評価者による違いがないことが分かりました。このことから、重複の特定においてはこの機械学習モデルが人間と同等であることが実証されたのです。このデータは機械学習モデルの改善に使用され、データ品質管理チームが新たな成果の正確性を確認しました。
私達はWorldCat内の重複書誌レコードを削減・解消するための継続的な取り組みの一環として、機械学習モデルを近日中に導入します。2023年8月下旬から、100万レコード-50万ペアの初回処理が機械学習アルゴリズムによって実行される予定です。これにより、50万件の重複書誌レコードがWorldCat上で統合され、図書館職員とエンドユーザーの双方にとって、目録作成、発見、図書館間相互貸借の体験が改善され、合理化されることになります。
プロジェクトに参加してくださったすべての方々に感謝します!皆様のご協力は、世界中の図書館の専門性と使命を向上させるのに役立っています。
*重複の概念は、重複を経験するユーザーに完全に依存します。この投稿で後述するラベリングプロジェクトは、2つの書誌レコードが類似しているかどうかを目録作成者に尋ねるものです。重複の正式な定義については、おそらく別の投稿が必要でしょう。
**レコード年代は、その資料の出版年代に相当します。DDRは、1830年以前に出版された資料については、その多くが稀覯本の目録規則に該当するため、別の規定を適用しています。
このブログ投稿は、OCLCのデータ品質管理部門の前部長であるネイサン・パットナム氏による共同執筆です。OCLC 研究図書館パートナーシップの上級プログラム担当役員であるリチャード・アーバン氏に謝意を表します。
当記事の詳細はこちらから≫
目次へ戻る▲
シリーズ:OCLCあの時この時 (5)
OCLCミュージアム収蔵品より「A whole new system of librarianship」
OCLC WorldCatに焦点をあてた図書館総合展特集号はOCLCミュージアムのバーチャル展示からOCLC創設者フレデリック G. キルゴアが残した一文で締めくくります。
以下はまだOCLCがOhio College Library Centerの略称で、オハイオ州立大学と周辺の大学図書館間でだけ利用されていた1973年6月に刊行した冊子「The Development of a Computerized Regional Library System. Final Report. June 1973」の結びにキルゴアが記したものです。

フレデリック・G・キルゴア著「電子化された地域図書館システムの開発. 最終報告書. 1973年6月」からの抜粋
「OCLCのオンラインコンピュータ地域図書館システムは、当初の目標を成功裡に達成することができたが、それは全く新しいライブラリアンシップ体制構築の始まりに過ぎないことを強調しておきたい。これからの数年間、さらに多くの研究、開発、実行を成し遂げなければならない。」
今年2023年はそれからちょうど50年です。技術革新のスピードはめまぐるしく、世界情勢や図書館を取り巻く環境も変化し続けていますが、それでもキルゴアの言葉は今も尚、図書館の仕事に携わる人の心に響き、成し遂げるべき事を考えるきっかけとなるのではないでしょうか。
OCLCミュージアムのバーチャル展示はこちらから≫
この文書の全文はこちらから≫
目次へ戻る▲
それでは、図書館総合展フォーラムでお会いできるのを楽しみにしております。
(紀伊國屋書店 OCLC事業部)
掲載の商品・サービスに関するお申し込み・お問い合わせ先
株式会社紀伊國屋書店 OCLC事業部
電話:03-6910-0514 e-mail:oclc@kinokuniya.co.jp