OCLC News 第72号
商品情報をはじめ、OCLCに関する様々な情報をご案内致します。
第72号はリンクトデータ特集です。
目次
はじめに–OCLCによるリンクトデータの取り組みについて
近年、図書館に関する情報源で「Linked Data」、「リンクトデータ」という言葉を目にする事が増えてきました。
以前から将来の書誌データはMARCからリンクトデータ形式に代わると言われていましたが、この数年間、目に見える形で将来のデータ形式への準備が行われてきています。
リンクトデータとはウェブ上の他のデータとのリンクが付いているデータという意味ですが、図書館が今まで努力して作成、維持してきた蔵書を記述するメタデータは残念ながらその状態にはなっていません。リンクトデータ化への取り組みとは、図書館のメタデータをウェブ標準と相互運用できるようにし、より多くの人々が利用するプラットフォームに公開するための試みと言えます。
今号のOCLC Newsでは、OCLCが取り組んでいる図書館データのリンクトデータ化に向けての取り組みをご紹介いたします。
OCLCが考えるリンクトデータが図書館にもたらす恩恵
図書館が持つ知識を外部につなげ、拡大する
リンクトデータを使用することで、図書館は、図書館の中だけで利用されていた情報資源を、システム間、キャンパス全体、コミュニティ全体、そしてウェブ全体といった、より広い情報の流れに、より簡単につなげることができ、その価値を示すことができます。
思いがけない発見を後押しする
リンクトデータは、記述の過程に文脈の概念を追加し、複雑な研究課題を解決するための新しいアプローチのような、予期せぬ発見につながる接点を生み出します。
価値の高い知識労働に重点をシフトする
リンクトデータへの移行は、発見可能性を補強する知識労働者としての図書館員の役割を拡大するものです。また、図書館が学内や地域社会における知識の創造と共有により関与できるようになります。
国際的な情報エコシステムに貢献する
リンクトデータは、図書館のメタデータを他のデータフォーマットやテクノロジーと調和させます。これにより、機械や新たなテクノロジーで利用できるようになり、最終的にはより見つけやすく、索引付けしやすく、共有しやすくなります。
図書館のデータをリンクトデータに進化させることで、図書館の蔵書が持つ情報が外部に向けて解放され、ウェブ上やスマートデバイス、人工知能(AI)などのテクノロジーを使って、私たちの日常生活に役立つ知識の奔流への合流が可能となります。
OCLCが行ってきたリンクトデータに向けての試みの一部
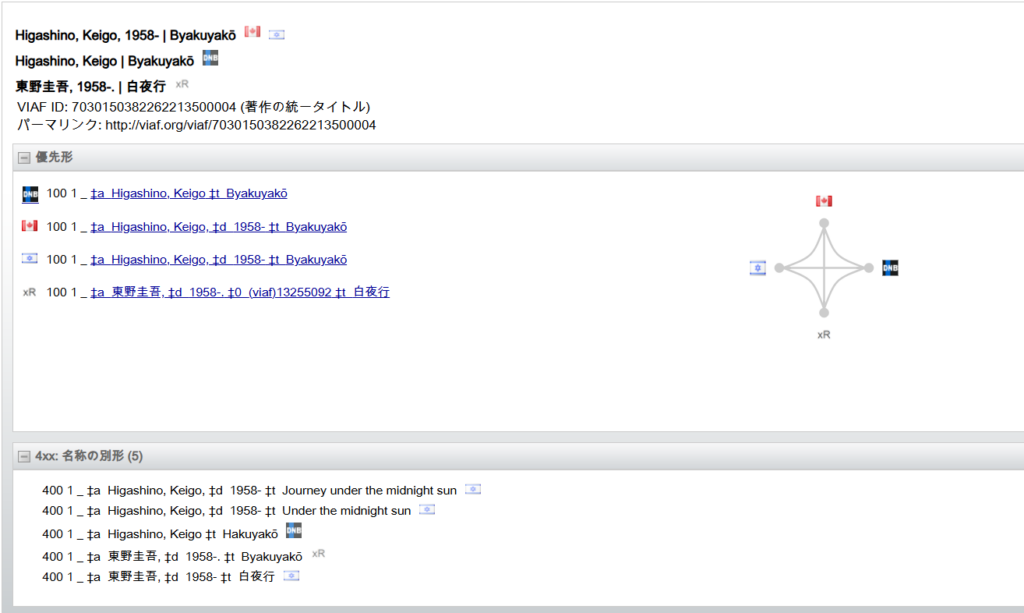
xRフラグの付いたVIAFレコードの例
- WorldCat Entities
WorldCat Entitiesは、リンクトデータの作成・編集作業のための、永続的、共有的、集中的なエンティティ (実体) 管理用インフラです。
個人、家族、団体、 出来事、場所などの実体に対する従来の様々な典拠レコード (VIAF含む) を固有のURIで包含し、リンクトデータ内で使用する事によって図書館という枠を超えたデータ利用を可能にしようとする取り組みです。現在、書誌レコード自体はMARC形式を継続していますが、このWorldCat Entitiesで付与されたURIは、WorldCat内の書誌レコードの100, 700 (名称のみ)、および600, 647, 651とタグ付けされたFAST標目のサブフィールド$1に自動、手動で日々追加されています。今年前半で4億件の書誌レコードがWorldCat Entities URIで強化されました。WorldCat Entitiesは無料で検索ができます。WorldCat Entitiesに実体データを新規に追加したり、既存データを編集するためのツールとして新しくMeridianがリリースされました。Meridianのご利用にあたってはご契約が必要です。
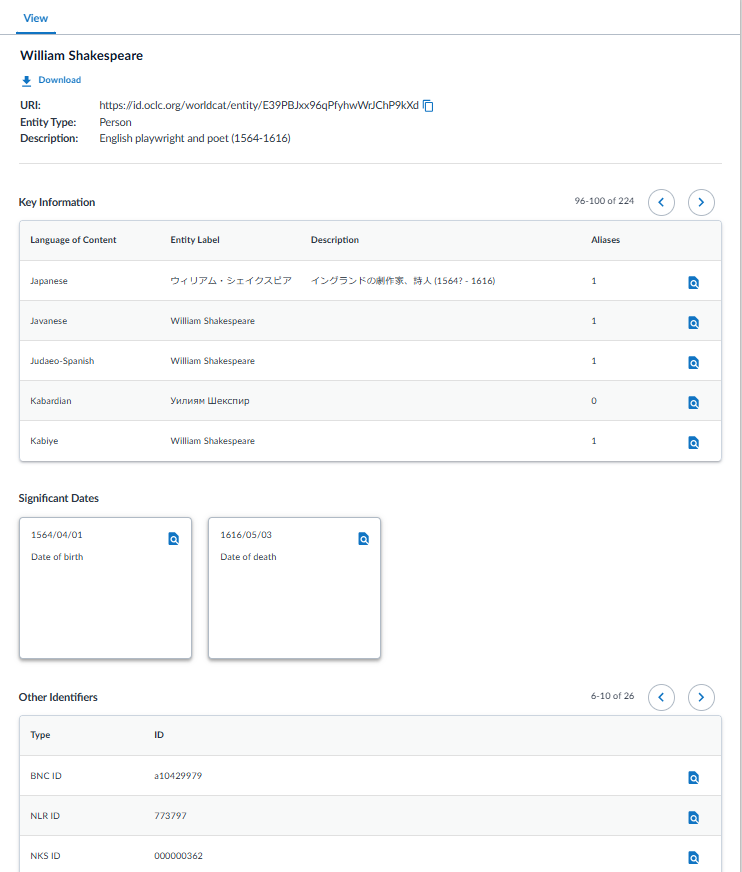
WorldCat Entitiesデータの例 (上部)
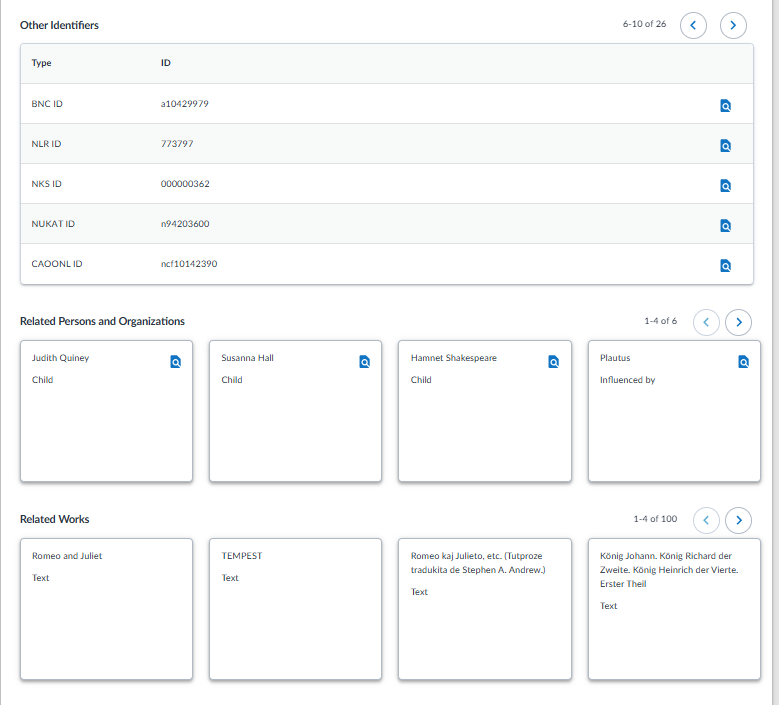
WorldCat Entitiesデータの例 (下部)
以下は、過去のOCLC Newsで扱ったリンクトデータ関連記事です。
23号: YouTubeでISNIナンバーが利用可能に
37号: OCLCがリンクトデータ管理構想を支援するインフラ整備に対してメロン財団の助成金を獲得
38号: OCLC Researchのリンクトデータ実験プロジェクト「Project Passage」
43号: リンクトデータはアーカイブ資料と特殊資料コレクションで進化する
44号: リンクトデータが図書館にもたらす恩恵
45号: メタデータは次世代へ移行する
50号: 次世代メタデータに関する初の英語円卓会議: 相互運用可能な図書館データのクリティカル・マスを目指して
51号: 次世代メタデータに関するオランダ語円卓会議: NACOやWorldCatを超える発想を
―OCLCのリーダーたちが知見や経験を共有するブログ Nextより―
図書館のリンクトデータ入門

ジェフ・ミクスター
Next掲載日: 2024年3月26日
私たちは先日、リンクトデータを図書館の目録作成ワークフローの主流にするための包括的な戦略を発表しました。これは長期的なアプローチであり、ほとんどの図書館がゆっくりと段階的にリンクトデータに移行していくだろうと認識しています。
私たちは世界中の図書館と緊密に協力することにより、一部の図書館の職員が既にこのトピックについて教育訓練を受け、リンクトデータサービスを試験的に導入し、また進行中の調査に参加していることを知っています。しかし、その他の多くの図書館が様々な疑問を抱いていることも知っています。技術的な問題に加えて、図書館員は、リンクトデータが現在行っている業務に対して間接的、直接的にどのような影響があるのかについて疑問を抱いています。その手助けとなるよう、OCLCは、図書館が現在直面している課題を解決し、有意義な解決策を提供するために、リンクトデータのインフラとサービスを展開しています。
リンクトデータとは?
最もシンプルに言うと、リンクトデータとは接続のことです。ウェブ上のデータを整理し、つなげることで、さまざまなシステムやサービスで、簡単に、自動的に、プログラムを通じて共有し、利用できるようにする方法です。
簡単でより技術的な説明は、この記事の最後にジャンプしてください。しかし、超簡単に言えば、リンクトデータとは、コンピュータが異なる概念を互いの関係性によってリンクさせるために使用する、標準化されたHTMLコード行のことです。
Googleの検索結果の「ナレッジパネル」を見ると、あるテーマについて多くの情報源からの情報が表示されていることがよくあります。その「情報カード」には、他の多くのサイトからのリンクトデータが入力されています(WorldCatからの情報を利用した、図書館リソースへの直接リンクも含まれます)。VIAF、Wikidata、DBpediaを含む他の関連リンクトデータソースは、サービスを接続し、新しいアプリケーションを作成するためにすでに使用されています。
より多くの関連リンクトデータがオンライン化されれば、図書館に特化したアプリケーションの追加機会が増えるでしょう。MARCレコードに閉じ込められた図書館に特化した貴重なデータを分割し、URI(Uniform Resource Identifiers:統一資源識別子)を使って公開することで、図書館スタッフは情報に対してより大きな文脈を提供できるようになり、図書館の蔵書とコミュニティ、そしてその先にある豊かなつながりを構築できるようになります。
リンクトデータはどう違うのでしょうか?より優れているのでしょうか?
MARCレコードのような従来の定型データフォーマットには、2つの大きな限界があります。図書館以外の情報源から有用なデータを図書館のワークフローに取り込むのは難しく、図書館情報の潜在的利用者がMARCデータをワークフローに取り込むのは困難です。
ひとつには、ご存知のように、図書館資料の発見と利用を向上させるための情報源は数多く存在するからです。その情報源は、学生や研究者により多く利用されている別の学部やシステムであったり、世界中の専門家であったりと、学内全域に及ぶ可能性があります。2 つ目は取り扱う機会がないことです。図書館のメタデータは、世界で最も有能なデータスペシャリストである(図書館やOCLCの)目録作成者によって作成されているためです。他の多くの産業や分野が、彼らの仕事の恩恵を受けることができるにも関わらずです。
リンクトデータは、両方の課題に対処するのに役立ちます。例えば、OCLCはGoogleのような組織と協力し、図書館のリンクトデータを彼らのサービスに組み入れています。このような努力により、人々がオンラインで検索する場所で、図書館の資料がより可視化されるようになります。また、図書館の職員と利用者がつながることのできるシステムやサービスに図書館の情報を取り込むことで、パートナーにも同じことを逆の立場で支援する機会が与えられます。例えば、リンクトデータは、言語を超えて著作をつなげることをより容易にします。つまり、出版社はある言語での問い合わせを他の言語で利用可能な資料に誘導することができます。
どちらの場合も、図書館の仕事をより広いウェブ環境へとつなげ、効率を高めながら図書館の存在感を高めるのに役立ちます。
MARCはどうでしょうか?
メタデータの歴史を見ると、図書館には、より多くの人がより多くの方法でメタデータと対話できるようなシステムやサービスに移行してきたという一貫した実績があります。
- 閉架書庫は究極のデータフィルタでした。利用者が閉架書庫から資料を取ってくるよう図書館職員に頼まなければならない場合、直接利用する機会はありませんでした。
- DeweyやLCC(米国議会図書館分類)のような体系を使って棚を通覧することで、利用者は自らメタデータと対話し、自ら選択することができるようになりました。図書館員はデータの門番という立場から、ガイド、教育者、支援者へと立場を変えました。
- WorldCatのような一元化されたデータベースは、共同でレコードを作成、改善するために図書館目録を連携させ、また図書館ベースのサービス内で新しい発見やリソースの共有オプションを提供しました。
- WorldCat.orgのような図書館データベースへのオンラインアクセスは、ウェブブラウザにアクセスできる人なら誰でも、図書館のメタデータをオンラインで見つけて利用できることを意味しました。初期のOCLCのパートナーシップは、図書館のデータが、いくつかの追加作業によって、他のオンラインリソースで共有できることも意味していました。
リンクトデータは、この進化の次のステップです。これまで私たちが行ってきたことは、主に図書館のメタデータに人々がアクセスできるようにすることでした。今、私たちは図書館のデータを、今日のオンラインサービスやプログラム、機械学習システム、人工知能(AI)アプリケーションにとってよりアクセスしやすい形で世に送り出しています。
MARCは当面、私たちと共にあるでしょう。結局のところ、多くの図書館が印刷カードからオンライン目録に完全に移行するのに50年近くかかりました。私たちの計画は、MARCベースの機能をサポートし続ける一方で、強力な図書館リンクトデータツールやリソースを積極的に構築していくことです。
なぜ今、リンクトデータにこだわる必要があるのでしょう?
図書館が知識の創造と共有を促進する新しい方法に焦点を当て続け、情報の量と種類が増えるにつれて、メタデータとメタデータの専門知識はこれまで以上に重要になっています。図書館のデータをリンクトデータに進化させることで、図書館の蔵書に眠る知識を解放し、ウェブ上やスマートデバイスを通じて、またAIなどのテクノロジーを使って、私たちの日常生活に役立つ知識の潮流へとつなげることができます。
現在、リンクトデータで起きていることに期待すべきだと考える理由:
- 何千もの機関で働く図書館員の専門知識を結集できます。これは、パートナーシップの面でも、独自研究の面でも、刺激的なことです。
- WorldCatは、図書館データを広範囲に同期し、強化します。WorldCat Entitiesは、書誌メタデータ管理のための文脈を確立する一元化されたデータセットです。また、DDC(Dewey Decimal Classification)やFAST(Faceted Application of Subject Technology)のような既存のシステムに接続し、リンクトデータを他の図書館ワークフローに統合しています。
- WorldCat Entities URIのようなデータをWorldCatに統合することで、現在のシステムやワークフローがリンクトデータに移行するのを支援します。
- 目録担当者が既存のレコードにリンクトデータを追加できるような新しいツールを作成中です。これにより、目録アプリケーションの強化、識別子を含むレコードの出力、そしてWorldCat Entitiesのリンクトデータ管理ツールであるOCLC Meridianの提供が間もなく開始されます。
- また、BIBFRAMEとMARCデータの間でシームレスに動作する書誌編集ツールを発表し、非MARCフォーマットへの移行に伴う図書館員の要望に応えます。
興奮することがたくさんあります。そして、これは短距離走ではなくマラソンになるでしょう。しかし、現在のところはどうでしょうか?OCLCは、それぞれのペースで移行するすべての図書館をサポートし、現在の業務プロセスに影響を与えることなく、価値を提供する方法でリンクトデータの未来に向けて取り組んでいることをご理解ください。
—
これはリンクトデータに関する3つの投稿のうちの最初のものです。OCLCリンクトデータ戦略およびニュースのメインページをチェックし、この重要なテーマに関する最新情報を得るためのご登録をお願いいたします。
リンクトデータの技術的背景
ティム・バーナーズ=リーと欧州原子核研究機構(CERN)のチームが1989年にウェブの基本プロトコルを考案したとき、彼らは人々とリソースをつなぐ3つの基本技術を提案しました。
- Unique resource identifiers (URL=統一資源識別子 )は、ウェブ上で接続可能なあらゆるもののための識別子で、一般に「ウェブページ名」として知られているURL (Uniform Resource Locator)はURIの一種
- Hypertext Markup Language (HTML) は、ウェブ上の文書を整形するために使われるコード
- Hypertext Transfer Protocol(HTTP)は、ウェブページと関連資源(画像、サウンド、ビデオ、アプリ、データ)間の接続を確立するために使用される通信規約
ウェブのユーザーであるあなたが、例えば「Boston Symphony Orchestra Archives」というリンクをクリックすると、関連情報が掲載された別のページに移動することを期待しています。その移動の文脈は、人々がどのように文書やリンクを使って関連リソースを探し、アクセスするかに基づいています。
その後、バーナーズ=リーはこれを発展させ、人間ではなくコンピュータ間でデータをリンクさせるための原則をまとめました。彼は、「概念的なもの」には、そのものに関するデータを標準フォーマットで返すオンライン上の名前としてURIをつけるべきであり、関連する他のものにもURIをつけるべきだと提案しました。こうすることで、人がリンクを使うのと同じように、コンピュータプログラムがページからページへ(URIからURIへ)移動し、共通の技術を使って関連情報を検索し、利用することができます。
ある「もの」(一般に「実体=エンティティ」と呼ばれ、もの、人、日付、概念、場所など何でもあり得る)のURIは、リンクトデータコードを持つウェブページにすぎません。そのコードには、主題に関する情報が含まれており、また「triple トリプル」と呼ばれるものを使って以下のように他の実体にリンクしています。
[Thing 1] <has this relationship> to [Thing 2]
例えば、
[Octavia E. Butler] <is the author of> [Parable of the Sower]
この情報は、バトラーと小説の両方のページにあるコードの一行に書かれています。そのため、コンピュータプログラムがどちらかのページを見つけると、その2つの実体の関係を「知る」ことができるようになります。そして、何十億ものリンクトデータが公開され、ウェブ上でつながれば、これまでバラバラだった情報を独自の強力な方法で利用するようなアプリケーションを構築することが可能になります。
例えば、別のサイトが有名人の出身地に関するリンクトデータを公開し、米国カリフォルニア州パサデナのページに次のようなトリプルを置くことが考えられます。
[Pasadena, California, USA] <is the birthplace of> [Octavia E. Butler]
そして第三のアプリケーションでは、休暇のプランニング用に多くのサイトからデータを取得して、興味深い旅行関連情報を表示するかもしれません。そのサービスは、生誕地のサイトからリンクトデータを引き出し、関連する面白そうなリンクを検索することが可能です。そのソフトウェアを使用してパサデナへの旅行を計画する場合、リンクトデータを検索し、図書館のデータに接続し、その都市出身の著者による作品への図書館リンクを提供します。
ここで覚えておくべきことは、リンクトデータとは、通常のウェブページ上にある、もの(「実体」)に関する文脈情報を提供するコンピュータコードにすぎないということです。そのデータは、自動化されたプログラムによって読み取られ、他の情報源からのリンクトデータと組み合わされ、新しいアプリケーションやサービスが作られます。
当記事の詳細はこちらから≫
目次へ戻る▲
―OCLCのリーダーたちが知見や経験を共有するブログ Nextより―
図書館がオンラインでより影響力を発揮するためにリンククトデータはどう役立つか

ジェフ・ミクスター
Next掲載日: 2024年4月30日
先日の投稿で、図書館のためのリンクトデータとOCLCの今後の計画についてご紹介しました。今日は、リンクトデータが図書館の蔵書における情報をいかに増幅させるか、そしてそれを実現するために使用できるツールの詳細を掘り下げてみましょう。
リンクトデータへのシフトは単なる技術のアップグレードではなく、図書館が収集・管理する貴重な資料の見つけやすさと利用しやすさを強化するための長期的な戦略です。技術的な挑戦であることは確かです。しかしこれは私たちの貴重な財産をより良くアピールする絶好の機会でもあるのです。
公開は易し、宣伝は難し
私たちは皆、信頼できる優れた情報を得るためには、低品質な作品や怪しげな情報源、信頼できない二次的な要約、その他の悪い選択肢の生い茂る藪をかき分けていかなければならない場合が多いことを知っています。また、低品質なのに主流かつ支配的なコンテンツがもつれ合っている中で、代表的でないコミュニティからの優れた情報を探し出し、アクセスすることが難しいことも分かっています。
ウェブは、コンテンツの制作と公開を民主化する素晴らしい仕事をしてきました。ブログ記事、ポッドキャスト、ビデオ、音楽を共有したい?あらゆる種類の無料オプションがあります。また、家族と写真を共有したり、日記をつけたり、近所のグループのためにアイデアを記録したりといった個人的な目的であれば、見つけやすさは問題になりません。
オープンウェブ上では何でも公開することが可能ですが、コンテンツが大量にあるため、多くの場合、独立したデータサイロに保存されている独自に管理されたコンテンツを見つけることは、大々的に宣伝されているか、(「バズる」コンテンツという意味で)非常に人気のあるプラットフォームを通じて提供されていない限り、困難です。
このような選択肢は、図書館が独自に管理している著作に対しては、ほとんどありえません。そこでリンクトデータの出番となるのです。
接続の自動化
情報がリンクトデータとして公開されると、自動コンテンツ生成システムによって、より多くの方法で見つけられ、利用されるようになります。
リンクトデータは、発見と経済の透明性の両方を促進するために、何年も前からこのように使われてきました。リンクトデータは、参加組織間の一種の「自動コラボレーション」を促進します。例えば、
- Googleナレッジグラフ: 検索結果の横に表示される情報とリンクのスニペットで、ユーザーはよくある質問にアクセスできます。
- ウィキデータ: ウィキペディアなどのウィキメディア・プロジェクトのために共有化されたリンクトデータストア
- 英国放送協会(BBC): BBCは、独自のプラットフォームと広範なウェブ上での発見を容易にするために、リンクトデータを使用してコンテンツライブラリを体系化しています。
- 小売企業: Best Buy社や その他の小売企業はSchema.orgのリンクトデータを利用してSEOを強化し、サプライチェーン全体の効率化を図っています。
- 科学のいくつかの分野における学術活動: リンクトライフデータ(LLD)やBio2RDFなどです。
図書館にとってリンクトデータは、主要なウェブサービス、学術部門や専門分野、研究活動との統合を促進します。以前はサイロ化されたアプリケーションに保持されていた情報を「解き放つ」ことで、リンクトデータは新しい状況での発見の自動化と、利用者にとって最良の結果を容易に提供することを可能にします。
OCLCと現在の図書館リンクトデータ環境
2000年代半ば、OCLCは図書館資料をウェブ上で見つけやすくするための方法で、データの変換と共有を開始しました。OCLC ResearchチームとResearch Library Partnership (RLP)は、図書館のリンクトデータとプロトタイプに関する最重要の研究を行ってきました。これには、リンクトデータの方法とプロセスをテストしたProject Passageが含まれます。これらの取り組みの一環として、私たちはWorldCatのレコードに直接、また他のワークフロー内にリンクトデータ要素を追加してきました。
今年初め、OCLCは大きな一歩を踏み出し、WorldCat EntitiesのリンクトデータがWorldCatの書誌レコード内で見られるようになったことを発表しました。これらのURI(統一資源識別子)は、作品、人、組織、場所、出来事、およびその他の実体に関する従来のMARCデータフィールドを定義し、より広範なリンクトデータ環境に結びつけます。その結果、OCLCで目録を作成するすべての図書館は、このより開放的で有用な技術によって可能になった新しい接続から利益を得ることができます。
これは画期的なことです。OCLCとそのメンバーである図書館が60年以上にわたって作成し、改良してきた何億ものレコードが一挙に、教育・図書館分野の内外のプラットフォームや サービスによってより利用しやすく、アクセスしやすくなるのです。
研究と恩恵
また、リンクトデータへの移行は、図書館のサービスやプログラムについて新たな発想を生み出すような新しい形の比較やコンテクストを可能にし、エキサイティングな研究の機会をもたらします。OCLCはこの探求の最前線に立ち続け、図書館とその利用者にとっての利点を理解し最大化することを追求し、図書館の蔵書に眠る知識を、私たちの生活に情報を与えるより大きく国際的な知識グラフにつなげるために必要なツールとインフラを提供します。
このすべての変化が素晴らしいものであるのと同時に、私たちはしばらくの間、複合的目録環境で仕事をすることになるでしょう。インフラとワークフローの移行には時間がかかります。技術的な導入だけでなく、より重要なのは、次世代型のナレッジワークを効果的に行うために学び、成長しなければならない人材を支援することです。
私たちの目標は、目録システムや インフラが過度な負担や出費を必要としない形で改善される一方で、図書館がそれぞれのペースで前進できるような橋渡しをすることです。例えば、Meridianの立ち上げが間近に迫っていることは、目録担当者やその他の図書館のメタデータ担当者が、WorldCat Entitiesに新しい実体(Entity)や典拠(Authority)情報を追加できるようになることを意味します。このような改善により、MARCレコードも強化されます。
リンクトデータは、図書館メタデータの新しいフォーマットというだけではありません。それは、図書館のデータがどのように世界と相互作用するかという根本的かつ本質的な転換を意味します。それは、図書館のリソースをこれまで以上にアクセスしやすく、発見しやすく、影響力のあるものにするという取り組みです。
図書館のパートナーの皆様、会員の皆様、そしてOCLCの同僚とともにこの歩みを進めていけることに興奮しています。そして、これからも世界のメタデータコミュニティとともに学び、成長を続けていきたいと思います。
共に何を成し遂げられるか、楽しみで仕方がありません。
当記事の詳細はこちらから≫
目次へ戻る▲
―OCLC ResearchのブログHanging Togetherより―
キルトをご一緒に、OCLCで
Hanging Together投稿日: 2024年6月12日
レベッカ・プライアント
今月末にサンディエゴで開催されるアメリカ図書館協会の年次大会にご参加の方は、色とりどりのキルトの展示にご注目ください。毎年ALA ビブリオキルターズは、MLIS (図書館情報学修士号) の学生に毎年5,000ドルの奨学金を授与するクリストファー・ホイ/ERT奨学基金の資金調達のため、キルトの入札式競売を開催しています。
そこには、OCLCキルターズから寄贈された480のブロックと2500以上のピースで構成されたカラフルなカラーウォッシュスタイルのキルト 「Quilting Together」が展示されています。このキルトは、組織全体から集まった12人のOCLCの現職員と退職者のチームによってデザインされ、つなぎ合わせられ、組み立てられ、資金面でのサポートも受けました。各キルト作成者が3インチのブロックを作るために自分のとっておきの場所から色々な端切れを掘り出し、それが縫い合わせられてこのカラフルでユニークな作品が出来上がりました。
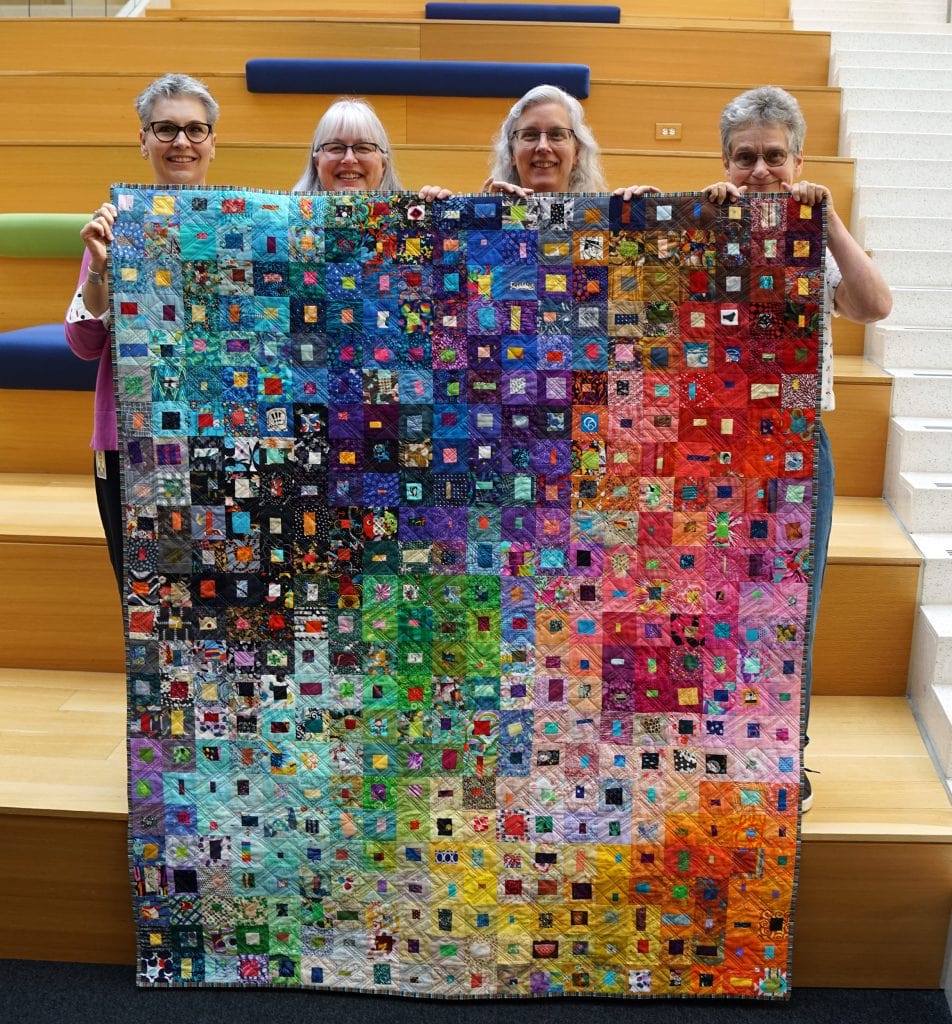
12人のOCLCキルターメンバーの内4人により披露された「Quilting Together」キルト
これはOCLCキルターズによる最初の作品ではありません。昨年、私たちはまさにWorldCatに触発されて、「World of cats」と名付けた猫をテーマにしたスクラップキルトを制作しました。これは奨学金を支援するにあたって775ドルの寄付金を集めました。
今年のキルトもWorldCatから着想を得ています。このキルトのタイトル 「Quilting Together」は、世界中の200以上の図書館が所蔵するWorldCat中のタイトル「Quilting together : how to organize, design, and make group quilts」から拝借しました。そして、この本のレコードやWorldCatの全てのレコードと同様に、このキルトはデータによって裏付けられています。数字をモチーフとした裏地をご覧ください!

データに着想を得たキルトの裏地
グループキルトを作るには、特別な配慮が必要です。例えば、誰でも参加できるようにするためには、選択される模様は多様なスキルの人が対応できるようシンプルなものでなければなりません。さらに、スクラップキルトのスタイルなら、参加者は材料を購入することなく、自分の「秘蔵場所」にある余ったキルトの端切れを使うことができます。材料が必要な人のために、経験豊富なキルト作家から十分な量の端切れが寄付されました。最後に、他の協同作業と同様、全員が同じように貢献する必要はないことを認識しておくことが重要です。キルト作りの全工程に参加した者もいれば、ブロック作りで貢献した者もいれば、プロにロングアーム・キルトミシン (キルティングの工程専用ミシン) のための費用を寄付した者もいます。

キルトに組み込まれたOCLCのロゴ
ある目録担当の同僚は、グループキルトはWorldCatにおける目録作成と似ていると指摘してくれました。そしてキルトは、書誌レコードと同じように、ブロック (ピースを縫い合わせてできた一つのパターン、あるいはパターンを何枚か縫い合わせたかたまり)、バッキング (裏布)、バインディング (端の始末の方法) など、独自の用語を持つ多くの構成要素からできています。私はそこが気に入っています。
サンディエゴで開催されるキルトオークションに立ち寄るだけでなく、ぜひお財布を出して入札してください。図書館における協働というビジョンにコミットしているグループによって作られた、世界にひとつだけのアイテムを手に入れることができるのです。もちろんキルトも。
当記事の詳細はこちらから≫
目次へ戻る▲
(紀伊國屋書店 OCLC事業部)
掲載の商品・サービスに関するお申し込み・お問い合わせ先
株式会社紀伊國屋書店 OCLC事業部
電話:03-6910-0514 e-mail:oclc@kinokuniya.co.jp